
- A+
这里把各种资料里认为和容错有关的概念放在一起来解释,这样或许能更好的理解Flink强大的容错机制。主要的概念有四个:Stage、Checkpoint、SavePoint、Barrier。
Flink容错
Apache Flink 提供了可以恢复数据流应用到一致状态的容错机制。确保在发生故障时,程序的每条记录只会作用于状态一次(exactly-once),当然也可以降级为至少一次(at-least-once)。
容错机制核心通过持续创建分布式数据流及其状态一致性的快照来实现。对于状态占用空间小的流应用,这些快照非常轻量,可以高频率创建而对性能影响很小。流计算应用的状态保存在一个可配置的环境,如:master 节点或者 HDFS上。
在遇到程序故障时(如机器、网络、软件等故障),Flink 停止分布式数据流。系统重启所有 operator ,重置其到最近成功的 checkpoint。输入重置到相应的状态快照位置。保证被重启的并行数据流中处理的任何一个 record 都不是 checkpoint 状态之前的一部分。
注意:为了容错机制生效,数据源(例如 消息队列 或者 broker)需要能重放数据流。Apache Kafka 有这个特性,Flink 中 Kafka 的 connector 利用了这个功能。由于 Flink 的 checkpoint 是通过分布式快照实现的,接下来我们将 snapshot 和 checkpoint 这两个词交替使用。
状态(State)
状态是为了解决“有过程”的计算场景下故障恢复用的。什么是“有过程”,如果在dataflow中,一次只计算一条数据,此时出现故障,只需要重新消费一次即可,但如果在一个窗口内,一次有很多数据需要计算,对于中间的计算结果保存下来,方便故障时进行“断点恢复”,那么这些操作就成为stageful(有状态的),后端存储(State Backend)默认RocksDB。

operator 包含任何形式的状态,这些状态都必须包含在快照中。状态有很多种形式:
1、用户自定义状态:由 transformation 函数例如( map() 或者 filter())直接创建或者修改的状态。用户自定义状态可以是:转换函数中的 Java 对象的一个简单变量或者函数关联的 key/value 状态。
2、系统状态:这种状态是指作为 operator 计算中一部分缓存数据。典型例子就是: 窗口缓存(window buffers),系统收集窗口对应数据到其中,直到窗口计算和发射。
operator 在收到所有输入数据流中的 barrier 之后,在发射 barrier 到其输出流之前对其状态进行快照。此时,在 barrier 之前的数据对状态的更新已经完成,不会再依赖 barrier 之前数据。由于快照可能非常大,所以后端存储系统可配置。默认是存储到 JobManager 的内存中,但是对于生产系统,需要配置成一个可靠的分布式存储系统(例如 HDFS)。状态存储完成后,operator 会确认其 checkpoint 完成,发射出 barrier 到后续输出流。快照现在包含了:
1、对于并行输入数据源:快照创建时数据流中的位置偏移
2、对于 operator:存储在快照中的状态指针

检查点(Checkpoint)
Flink使用stream replay和checkpointing来实现容错。Checkpoint通过对stream和operator都做快照(snapshot)来记录状态,这样才能够在保证在流处理系统失败时能够正确地恢复数据流处理。Checkpoint是Flink周期性自动做的,支持全量和增量。
保存点(Savepoint)
Savepoint和Checkpoint类似,是用来保存程序和Flink Cluster的State(状态),它和Checkpoint的主要区别有两点:
1. 手动触发生成
2. 不会自动过期
可以通过命令行或REST API的方式来创建Savepoint。
Barrier机制
Flink分布式快照的核心概念之一就是Barrier(数据栅栏)。这些Barrier被插入到数据流中,作为数据流的一部分和数据流一起向下流动。Barrier不会干扰正常的数据,数据流严格有序。一个Barrier把数据流分割成两部分:一部分进入到当前快照,另一部分进入到下一个快照。每个Barrier都带有快照ID,并且Barrier之前的数据都进入了此快照。Barrier不会干扰数据流处理,所以非常轻量。多个不同快照的多个Barrier会在流中同时出现,即多个快照可能会同时被创建。

Barrier在数据源读入的时候被插入,当snapshot n的Barrier插入后,系统会记录当前snapshot在数据源中的位置n(用Sn标识)。比如,在Kafka中,这个变量标识某个分区中的最后一条数据的偏移量(offset)。这个位置值Sn会被发送到一个称为checkpoint coordinator的模块(即Flink的JobManager)。
然后Barrier随着正常数据继续往下流动,当一个operator从其所有的输入流都接收到snapshot n的Barrier时,它会向其所有输出流插入一个标识(也叫snapshot n)的Barrier。当sink operator(即DAG流的终点)从其输入流接收到所有的Barrier n时,表示这一批数据处理完成,它会向checkpoint coordinator发送消息确认snapshot n已完成。当所有sink都确认了这个snapshot,则标识本次处理已成功,该snapshot被标识为已完成。
在上诉处理流程中,operator上游会接收很多流,每个流的快慢又不一致,如何保证每个snapshot都都能放在一起被输出呢?这就靠operator的“对齐(align)”功能。
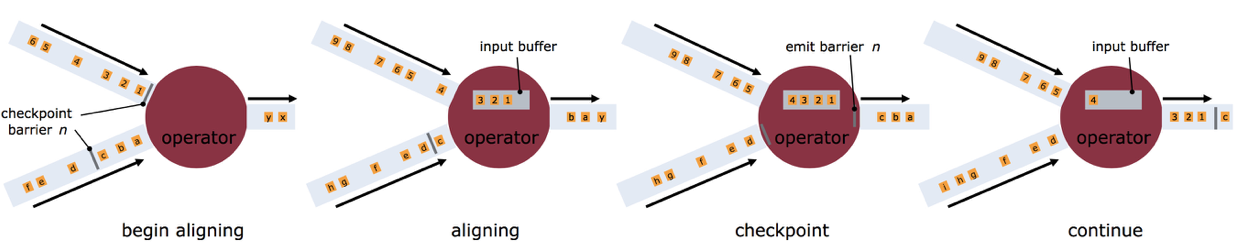
上图解释了“align”的过程,核心思想就是“快流等慢流”,拿barrier n来说,上面的流到的早,此后operator就暂时不会继续处理后续的数据了(否则会导致snapshot n和snapshot n+1的数据混在一起了),而是会用“input buffer”把它对应的数据先保存起来,等下面流的barrier n也到来时,operator就把内部的所有数据都向下发出去,并对下游也插入一个barrier n来标识本次对齐完成。
基于Stream Aligning操作能够实现Exactly Once语义,但是也会给流处理应用带来延迟,因为为了排列对齐Barrier,会暂时缓存一部分Stream的记录到Buffer中,尤其是在数据流并行度很高的场景下可能更加明显,通常以最迟对齐Barrier的一个Stream为处理Buffer中缓存记录的时刻点。在Flink中,提供了一个开关,选择是否使用Stream Aligning,如果关掉则Exactly Once会变成At least once。
Recovery
在这种容错机制下的错误回复很明显:一旦遇到故障,Flink 选择最近一个完成的 checkpoint k。系统重新部署整个分布式数据流,重置所有 operator 的状态到 checkpoint k。数据源被置为从 Sk 位置读取。例如在 Apache Kafka 中,意味着让消费者从 Sk 处偏移开始读取。
如果是增量快照,operator 需要从最新的全量快照回复,然后对此状态进行一系列增量更新。
参考资料
https://www.iteblog.com/archives/1987.html
![流式计算框架容错和高性能如何兼得[转]](/wp-content/uploads/2018/08/flink-daishu_2018.08.02.png)


