
- A+
Levels of Abstraction
“流”并不是一个新的概念,视频流、音频流很多场景都用到了这个概念,这里主要理解“流式计算”和“批次计算”的区别,流式没有边界的,实时性更强,但相应对于failover等机制,流式计算更难控制,在诸多流式计算框架中Flink目前很好的已经解决了这些问题。最简单的理解“流式计算”可以认为它是由一组数据流和运算符组成的DAG(有向无环图)或拓扑图。
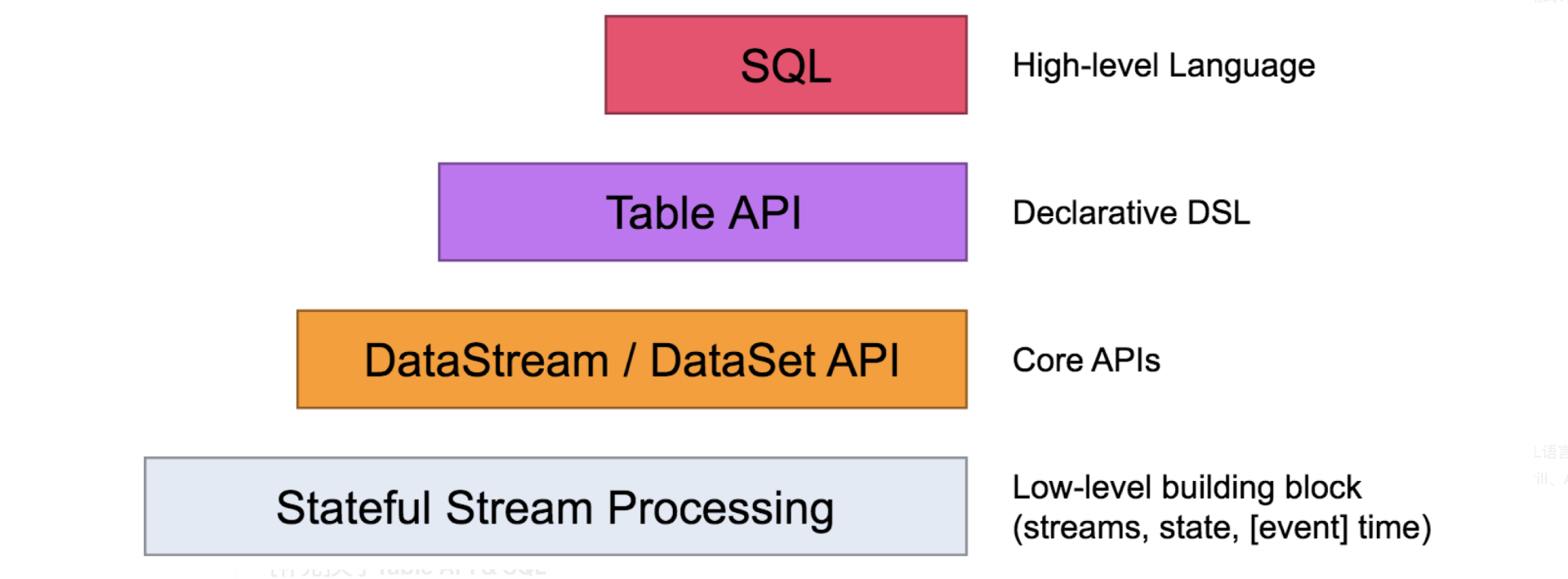
Flink提供了不同的抽象层来满足使用者开发流式/批次计算。
-
Stageful Stream Processing:最低抽象级别的API一般不会用到,它实际是Flink操作的原语,我们开发过程中更多使用上层的封装
-
DataStream/DataSet API:这是Flink的核心API,其中DataStream API既可以处理流式计算也可以处理批次计算,DataSet API用来处理批次计算。
-
Table API:Table API和SQL API是两种基于核心API的扩展,都支持对流式计算和批次计算的任务处理,其中Table API主要是Scala或Java代码来使用,SQL API通过标准的SQL语言来查询。
-
SQL:SQL语义的查询实际是Flink对查询API的扩展,SQL语言一直被业界认为在查询系统中最合适的一种方式,很多查询系统(包括Apache Flink、Apache Kylin、Apache Drill、Apache Hive、Apache Kylin、Apache Phoenix、Apache Samza以及我们自己开发的DWS)都是基于Apache Calcite构建的。(Flink中的SQL API部分主要是由Alibaba Blink团队主导开发的)
[补充]关于Table API & SQL
Table API 是一种关系型API,类 SQL 的API,用户可以像操作表一样地操作数据,非常的直观和方便。用户只需要说需要什么东西,系统就会自动地帮你决定如何最高效地计算它,而不需要像 DataStream 一样写一大堆 Function,优化还得纯靠手工调优。另外,SQL 作为一个“人所皆知”的语言,如果一个引擎提供 SQL,它将很容易被人们接受。这已经是业界很常见的现象了。值得学习的是,Flink 的 Table API 与 SQL API 的实现,有 80% 的代码是共用的。所以当我们讨论 Table API 时,常常是指 Table & SQL API。
Table & SQL API 还有另一个职责,就是流处理和批处理统一的API层。Flink 在runtime层是统一的,因为Flink将批任务看做流的一种特例来执行,这也是 Flink 向外鼓吹的一点。然而在编程模型上,Flink 却为批和流提供了两套API (DataSet 和 DataStream)。为什么 runtime 统一,而编程模型不统一呢? 在我看来,这是本末倒置的事情。用户才不管你 runtime 层是否统一,用户更关心的是写一套代码。这也是为什么现在 Apache Beam 能这么火的原因。所以 Table & SQL API 就扛起了统一API的大旗,批上的查询会随着输入数据的结束而结束并生成有限结果集,流上的查询会一直运行并生成结果流。Table & SQL API 做到了批与流上的查询具有同样的语法,因此不用改代码就能同时在批和流上跑。
内容参考自:http://wuchong.me/blog/2017/03/30/flink-internals-table-and-sql-api/,该博客作者也是Flink的committer。
Programs and Dataflows
Flink程序的基本构建块是streams和transformations(注意,DataSet在内部也是一个stream)。一个stream可以看成一个中间结果,而一个transformations是以一个或多个stream作为输入的某种operation,该operation利用这些stream进行计算从而产生一个或多个result stream。
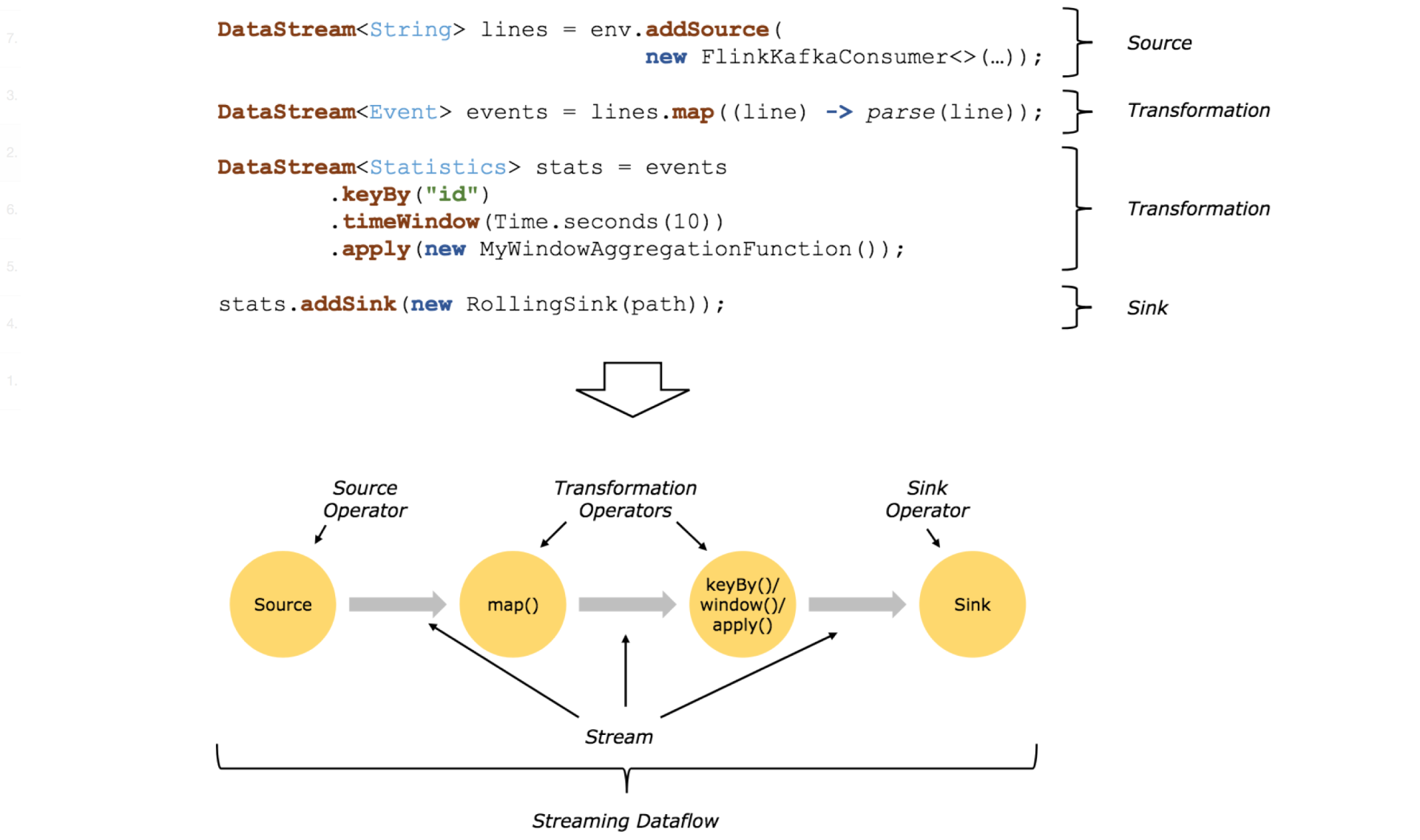
在运行时,Flink上运行的程序会被映射成streaming dataflows,它包含了streams和transformations operators。每一个dataflow以一个或多个sources开始以一个或多个sinks结束。dataflow类似于任意的有向无环图(DAG),当然特定形式的环可以通过iteration构建。在大部分情况下,程序中的transformations跟dataflow中的operator是一一对应的关系。但有时候,一个transformation可能对应多个operator。
Parallel Dataflows
程序在Flink内部的执行具有并行、分布式的特性。stream被分割成stream partition,operator被分割成operator subtask,这些operator subtasks在不同的线程、不同的物理机或不同的容器中彼此互不依赖得执行。
一个特定operator的subtask的个数被称之为其parallelism(并行度)。一个stream的并行度总是等同于其producing operator的并行度。一个程序中,不同的operator可能具有不同的并行度。
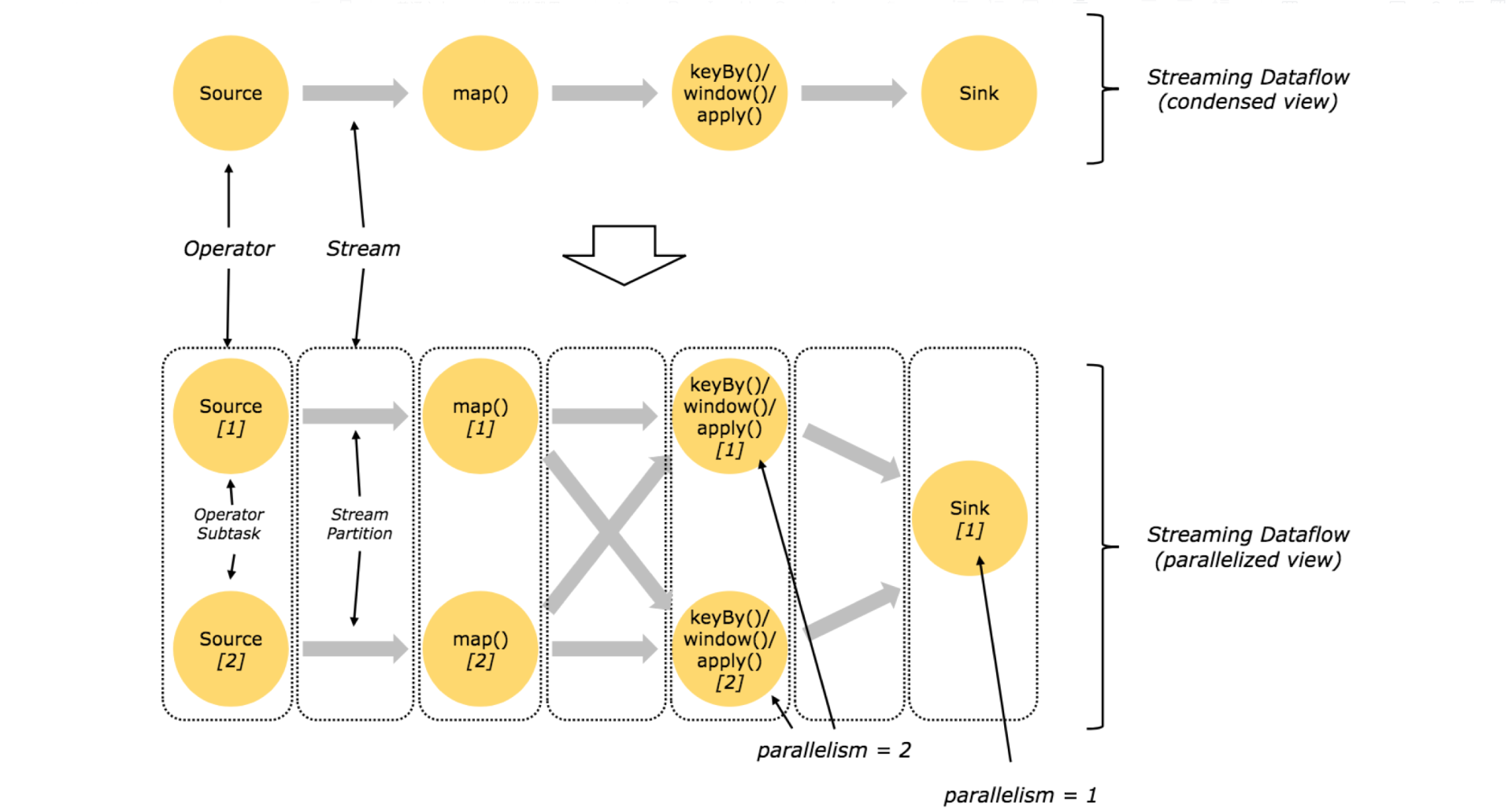
Stream在operator之间传输数据的形式可以是one-to-one(forwarding)的模式也可以是redistributing的模式。
-
One-to-one : strem(比如在source和map operator之间)维护着分区以及元素的顺序。那意味着map operator的subtask看到的元素的个数以及顺序跟source operator的subtask生产的元素的个数、顺序相同。
-
Redistributing : stream(map()跟keyBy/window之间或者keyBy/window跟sink之间)的分区会发生改变。每一个operator subtask依据所选择的transformation发送数据到不同的目标subtask。例如,keyBy() (基于hash码重分区),broadcast()或者rebalance()(随机redistribution)。在一个redistribution的交换中,只有每一个发送、接收task对的顺序才会被维持(比如map()的subtask和keyBy/window的subtask)。
Tasks and Operator Chains
为了更高效的分布式执行,Flink将operator的subtask链接在一起形成task。每个task在一个线程中执行。将operators链接成task是非常有效的优化:它能减少线程之间的切换、减少序列化/反序列化开销和基于缓存区的数据交换,在减少时延的同时提升吞吐量。链接的行为可以在编程API中进行指定。
以WordCount为例,看下面这幅图,Source的并行度为1,FlatMap、KeyAggregation、Sink并行度为2,最终以5个并行的线程来执行优化的过程。
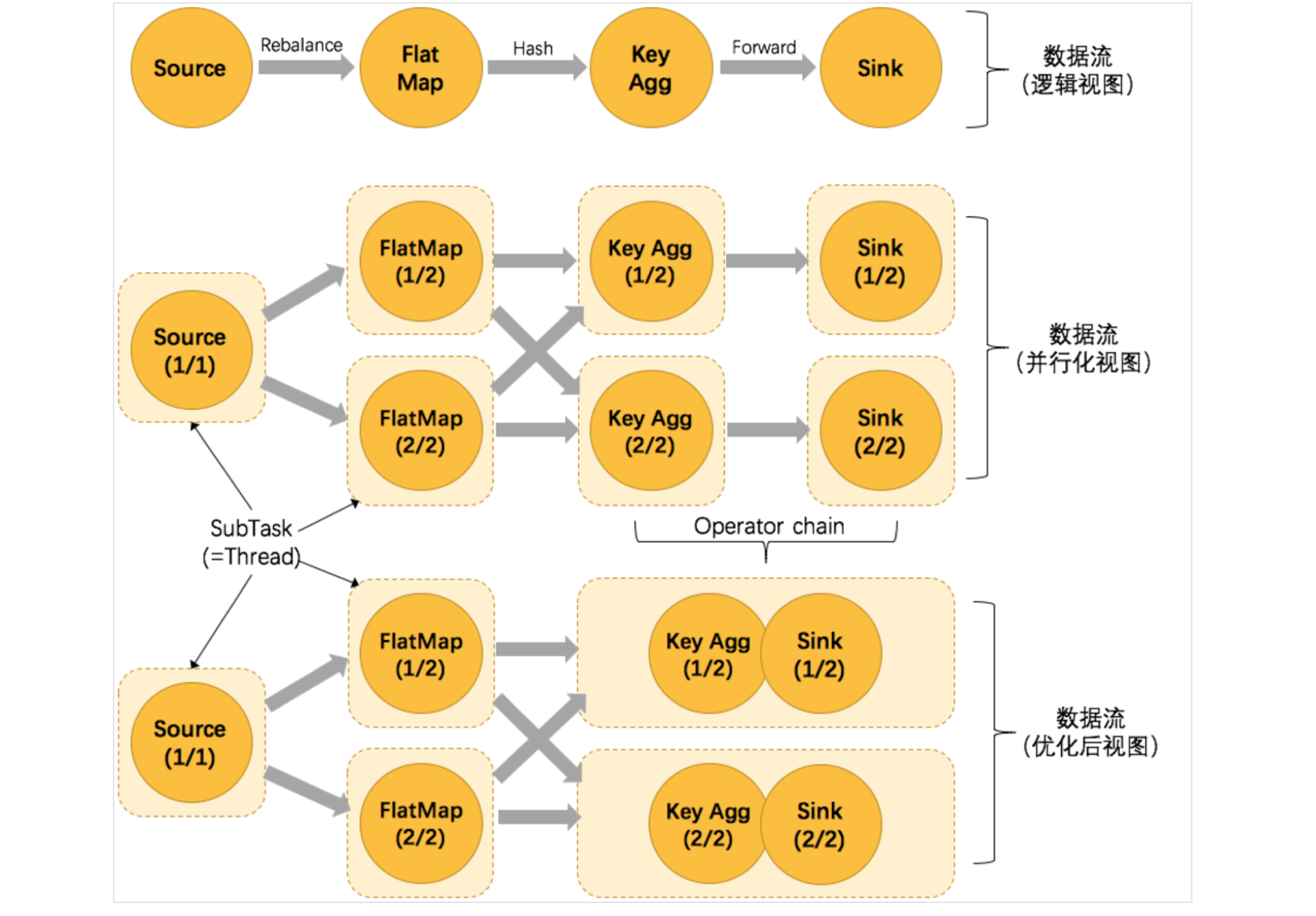
上图中将KeyAggregation和Sink两个operator进行了合并,因为这两个合并后并不会改变整体的拓扑结构。但是,并不是任意两个 operator 就能 chain 一起的。其条件还是很苛刻的:
-
上下游的并行度一致
-
下游节点的入度为1 (也就是说下游节点没有来自其他节点的输入)
-
上下游节点都在同一个 slot group 中
-
下游节点的 chain 策略为 ALWAYS(可以与上下游链接,map、flatmap、filter等默认是ALWAYS)
-
上游节点的 chain 策略为 ALWAYS 或 HEAD(只能与下游链接,不能与上游链接,Source默认是HEAD)
-
两个节点间数据分区方式是 forward(参考理解数据流的分区)
-
用户没有禁用 chain
Operator chain的行为可以通过编程API中进行指定。可以通过在DataStream的operator后面(如someStream.map(..))调用startNewChain()来指示从该operator开始一个新的chain(与前面截断,不会被chain到前面)。或者调用disableChaining()来指示该operator不参与chaining(不会与前后的operator chain一起)。在底层,这两个方法都是通过调整operator的 chain 策略(HEAD、NEVER)来实现的。另外,也可以通过调用StreamExecutionEnvironment.disableOperatorChaining()来全局禁用chaining。
关于Operator Chain的实现原理可参考:http://wuchong.me/blog/2016/05/09/flink-internals-understanding-execution-resources/
Window
窗口是为了解决对没有边界的数据进行聚合操作问题。对于batch类型的计算,能很方变的进行count、sum等操作,但对于stream,这种计算方式就比较困难,采用window来对数据进行隔离,比如“统计5分钟的数量”或“对最近100个元素求和”。
窗口分类
窗口可以是时间驱动(即Time Window)的(比如,每30秒)也可以是数据驱动(即Count Window)的(比如,每100个元素)。
另外一种方式将窗口可以分为三种:Tumbing window,Sliding Windows(有重叠)和session windows(有空隙的活动)。

结合具体实例来理解几种窗口含义:电商网站会记录每个用户每次购买的商品个数,我们要做的是统计不同窗口中用户购买商品的总数。
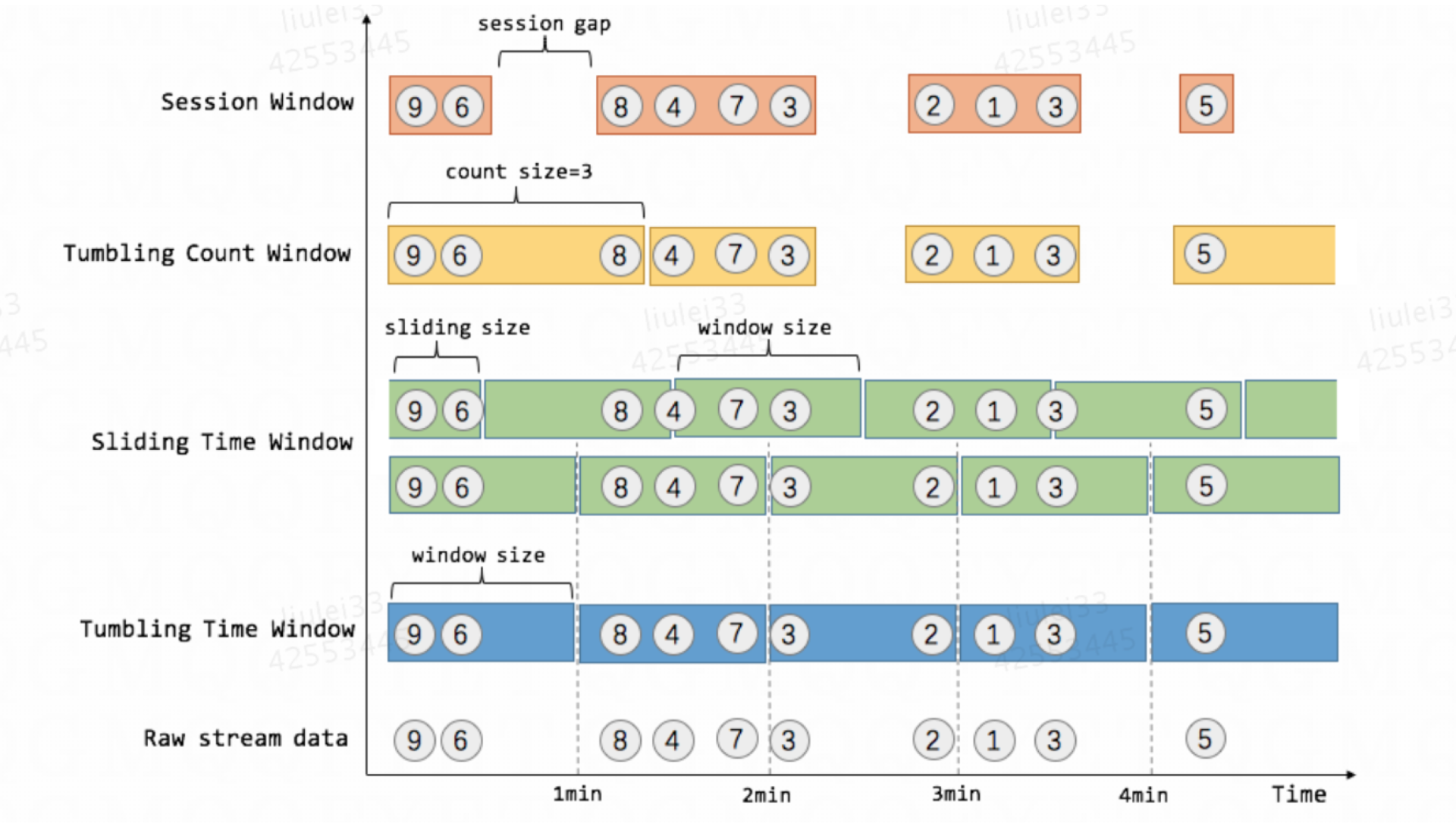
上图中,raw data stream 代表用户的购买行为流,圈中的数字代表该用户本次购买的商品个数,事件是按时间分布的,所以可以看出事件之间是有time gap的。
Tumbing Window(滚动窗口)
按固定大小来切分数据流,即在时间和窗口大小上都是固定的,相邻窗口没有重叠,也就是说数据要么在A窗口中,要么在B窗口中。
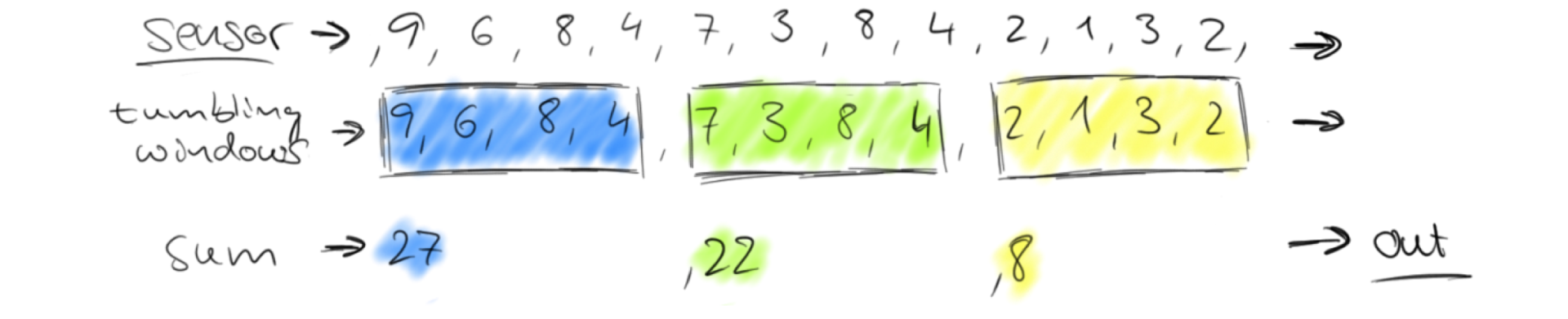
Tumbling Time Window
场景举例:每1分钟累加一次数据,将合并后的结果写入数据库。
// Stream of (userId, buyCnt) val buyCnts: DataStream[(Int, Int)] = ... val tumblingCnts: DataStream[(Int, Int)] = buyCnts // key stream by userId .keyBy(0) // tumbling time window of 1 minute length .timeWindow(Time.minutes(1)) // compute sum over buyCnt .sum(1)
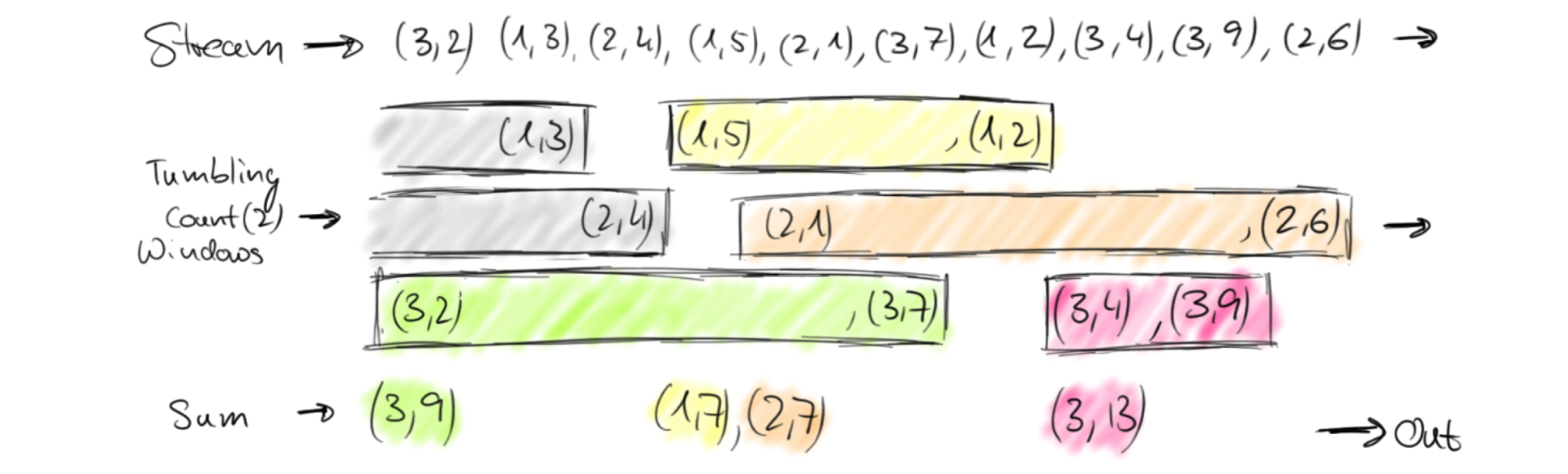
Tumbling Count Window
场景举例:每当窗口中填满100个元素了,就会对窗口进行计算
// Stream of (userId, buyCnts) val buyCnts: DataStream[(Int, Int)] = ... val tumblingCnts: DataStream[(Int, Int)] = buyCnts // key stream by sensorId .keyBy(0) // tumbling count window of 100 elements size .countWindow(100) // compute the buyCnt sum .sum(1)
Sliding Window(滑动窗口)
窗口大小不固定,而是按照一定的时间来“滑动”或“错位”。
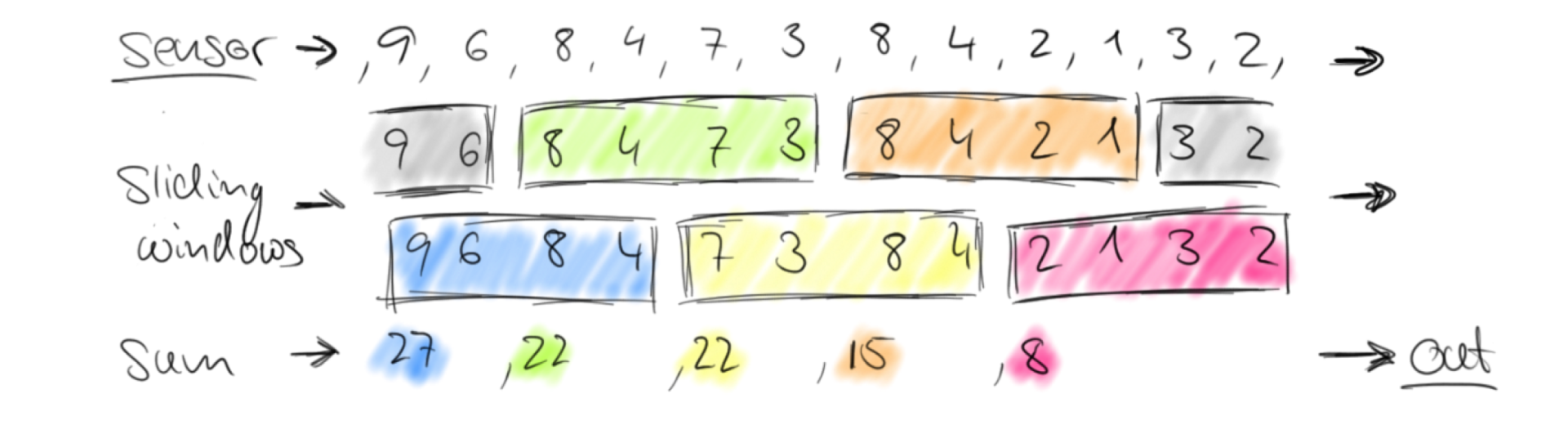
Sliding Time Window
场景举例:对于流数据,我们每隔30秒计算一次最后一分钟数据之和
val slidingCnts: DataStream[(Int, Int)] = buyCnts .keyBy(0) // sliding time window of 1 minute length and 30 secs trigger interval .timeWindow(Time.minutes(1), Time.seconds(30)) .sum(1)
Sliding Count Window
场景举例:计算每10个元素计算一次最近100个元素的总和
val slidingCnts: DataStream[(Int, Int)] = vehicleCnts .keyBy(0) // sliding count window of 100 elements size and 10 elements trigger interval .countWindow(100, 10) .sum(1)
Session Window(会话窗口)
类似Web应用中的Session,超过一段时间没有行为,就创建一个新的窗口。场景举例:场景一:对事件先按ID分流,然后对于每个流按照不同的session窗口统计。
场景二:统计每个用户在活跃起见共购买商品的数量,如果用户30秒没有任何购买行为,则该会话断开。
// Stream of (userId, buyCnts) val buyCnts: DataStream[(Int, Int)] = ... val sessionCnts: DataStream[(Int, Int)] = vehicleCnts .keyBy(0) // session window based on a 30 seconds session gap interval .window(ProcessingTimeSessionWindows.withGap(Time.seconds(30))) .sum(1)
提示:实际应用中以前两种为主,重点理解。关于session window,详细说明参考:http://wuchong.me/blog/2016/06/06/flink-internals-session-window/
Time
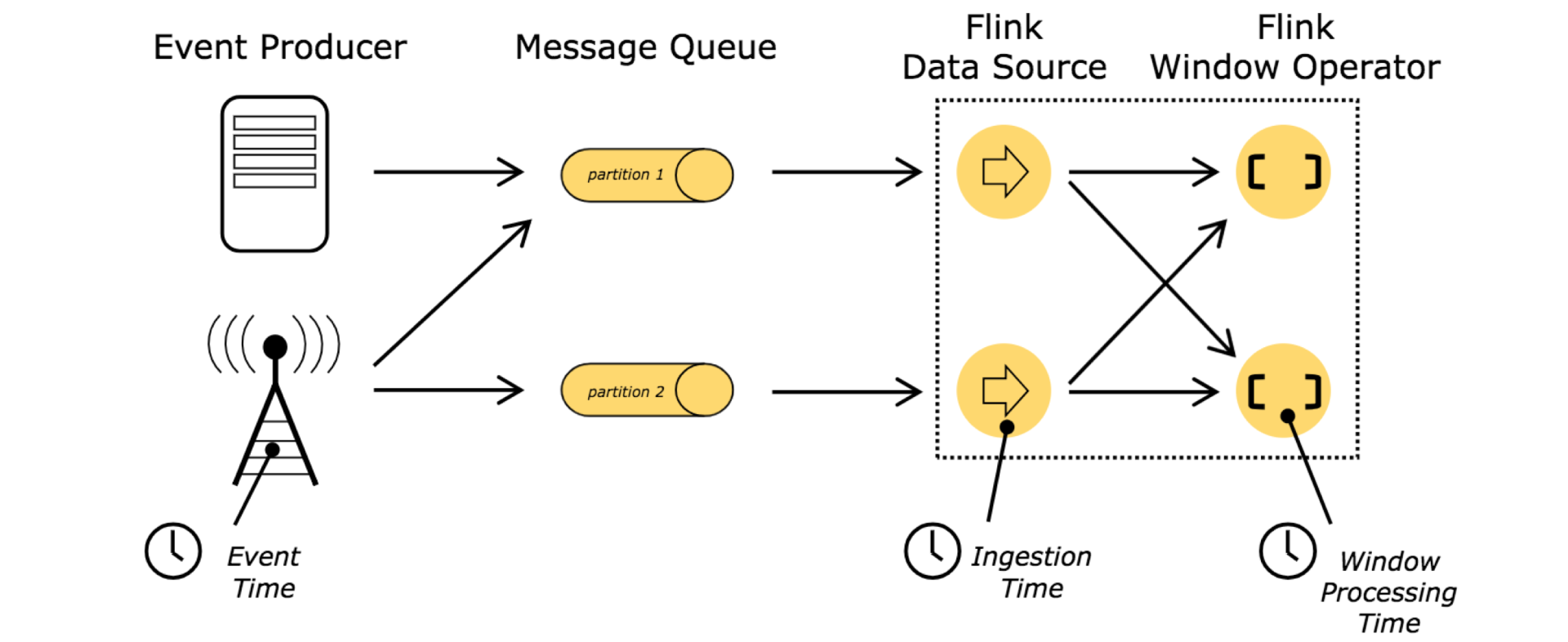
Flink提供多样性的时间选择,方便在不同业务场景的流式计算中灵活选择。常用时间类型有三种:
Processing Time(程序时间)
数据在Flink 的Operator中执行时的系统本地时间。(有些资料翻译为处理时间,即数据被处理的时长,这种理解应该不太正确)
Event Time(事件时间)
事件产生时间,比如服务器上报日志自带时间戳。
Ingestion Time(摄入时间)
数据读入Flink 时间,可以理解为数据进入Source Operator时刻的时间戳
提示:如果在代码中不配置Time类型,默认Processing Time类型。
如果需要修改,设置方式如下:
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime); //env.setStreamTimeCharacteristic(TimeCharacteristic.IngestionTime); //env.setStreamTimeCharacteristic(TimeCharacteristic.ProcessingTime);
Flink Architecture & Topology
基本架构
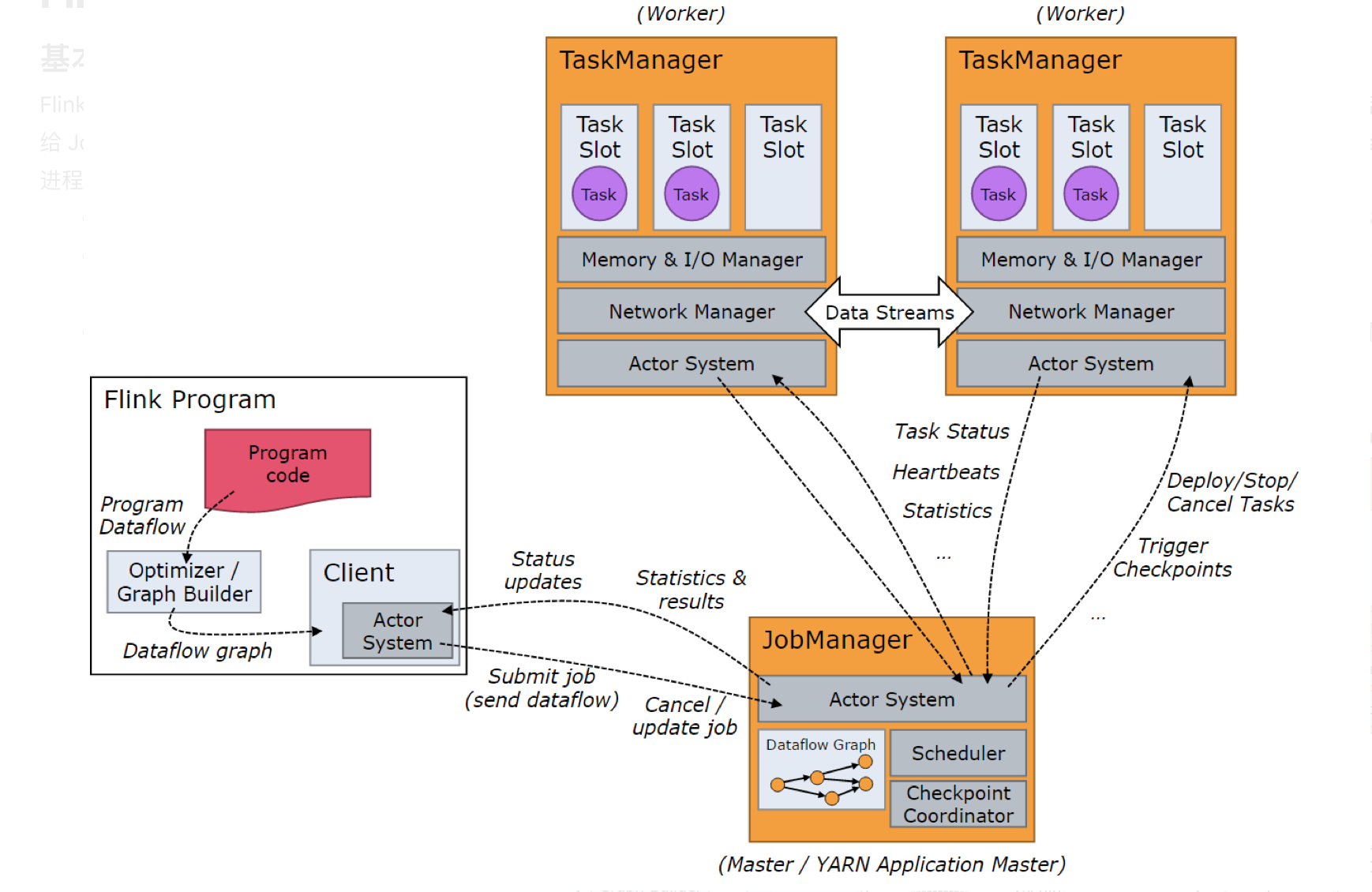
Flink也是主从模式,主要包括Master或JobManager、Worker或TaskManager,另外提交任务的是Clinet。当 Flink 集群启动后,首先会启动一个 JobManger 和一个或多个的 TaskManager。由 Client 提交任务给 JobManager,JobManager 再调度任务到各个 TaskManager 去执行,然后 TaskManager 将心跳和统计信息汇报给 JobManager。TaskManager 之间以流的形式进行数据的传输。上述三者均为独立的 JVM 进程。
-
Client 为提交 Job 的客户端,可以是运行在任何机器上(与 JobManager 环境连通即可)。提交 Job 后,Client 可以结束进程(Streaming的任务),也可以不结束并等待结果返回。
-
JobManager 主要负责调度 Job 并协调 Task 做 checkpoint,职责上很像 Storm 的 Nimbus。从 Client 处接收到 Job 和 JAR 包等资源后,会生成优化后的执行计划,并以 Task 的单元调度到各个 TaskManager 去执行。
-
TaskManager 在启动的时候就设置好了槽位数(Slot),每个 slot 能启动一个 Task,Task 为线程。从 JobManager 处接收需要部署的 Task,部署启动后,与自己的上游建立 Netty 连接,接收数据并处理。
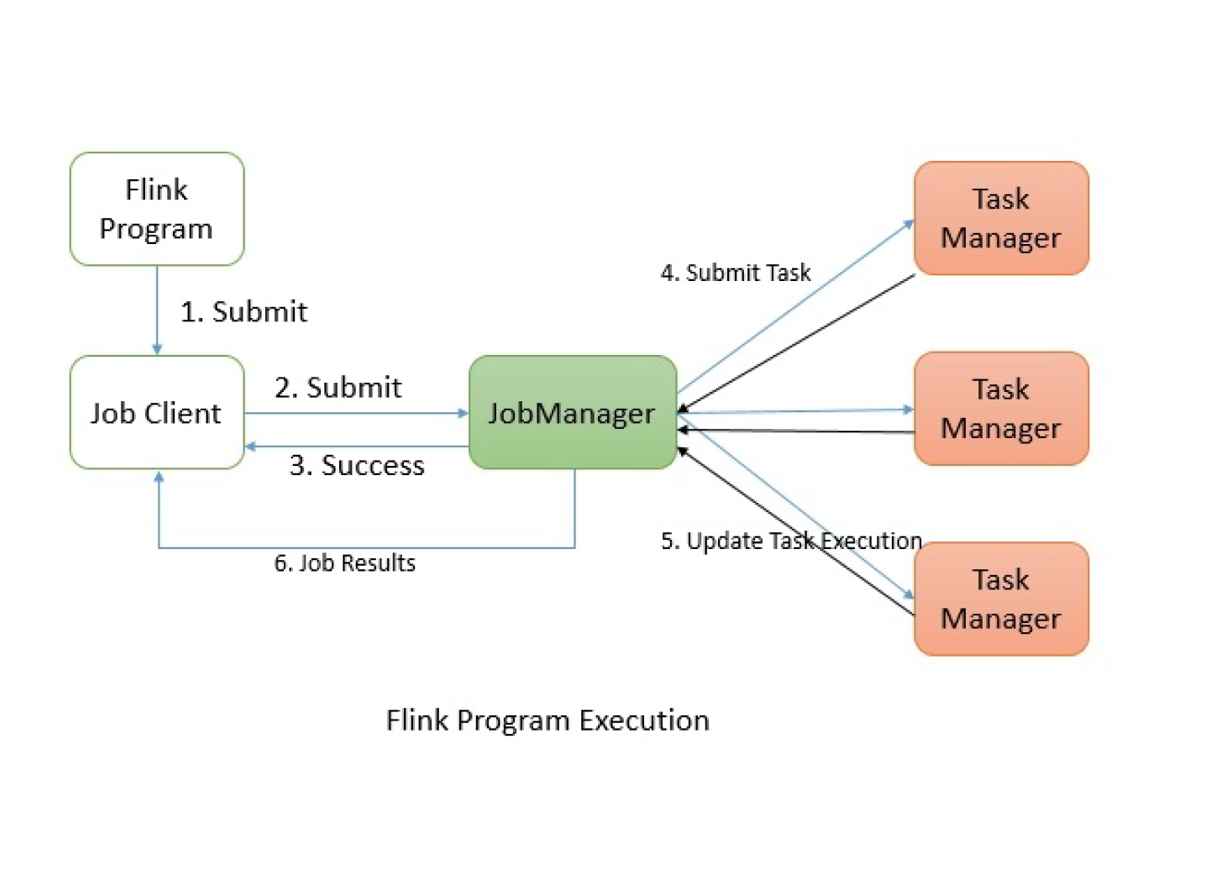
任务提交
Job Client会将任务以JobGraph形式封装,然后提交给JobManager,JobManager会进行一系列的资源分配、任务调度等操作,将任务分配给TaskManager,后者负责具体的执行,同时会定时汇报任务的执行状态,待任务执行完成后,将结果返回给客户端。
任务执行图
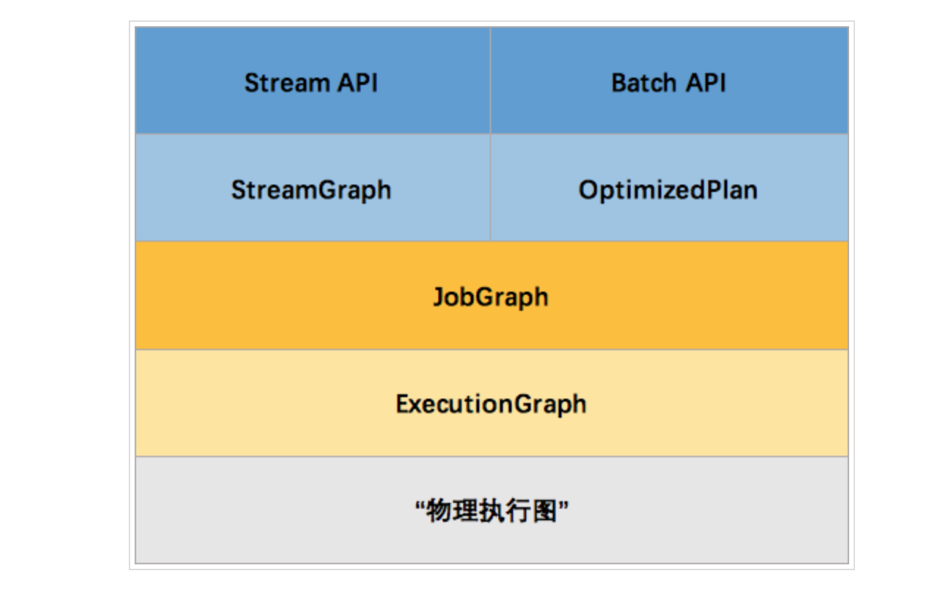
Flink 中的执行图可以分成四层:StreamGraph -> JobGraph -> ExecutionGraph -> 物理执行图。
-
StreamGraph:是根据用户通过 Stream API 编写的代码生成的最初的图。用来表示程序的拓扑结构。
-
JobGraph:StreamGraph经过优化后生成了 JobGraph,提交给 JobManager 的数据结构。主要的优化为,将多个符合条件的节点 chain 在一起作为一个节点,这样可以减少数据在节点之间流动所需要的序列化/反序列化/传输消耗。
-
ExecutionGraph:JobManager 根据 JobGraph 生成ExecutionGraph。ExecutionGraph是JobGraph的并行化版本,是调度层最核心的数据结构。
-
物理执行图:JobManager 根据 ExecutionGraph 对 Job 进行调度后,在各个TaskManager 上部署 Task 后形成的“图”,并不是一个具体的数据结构。
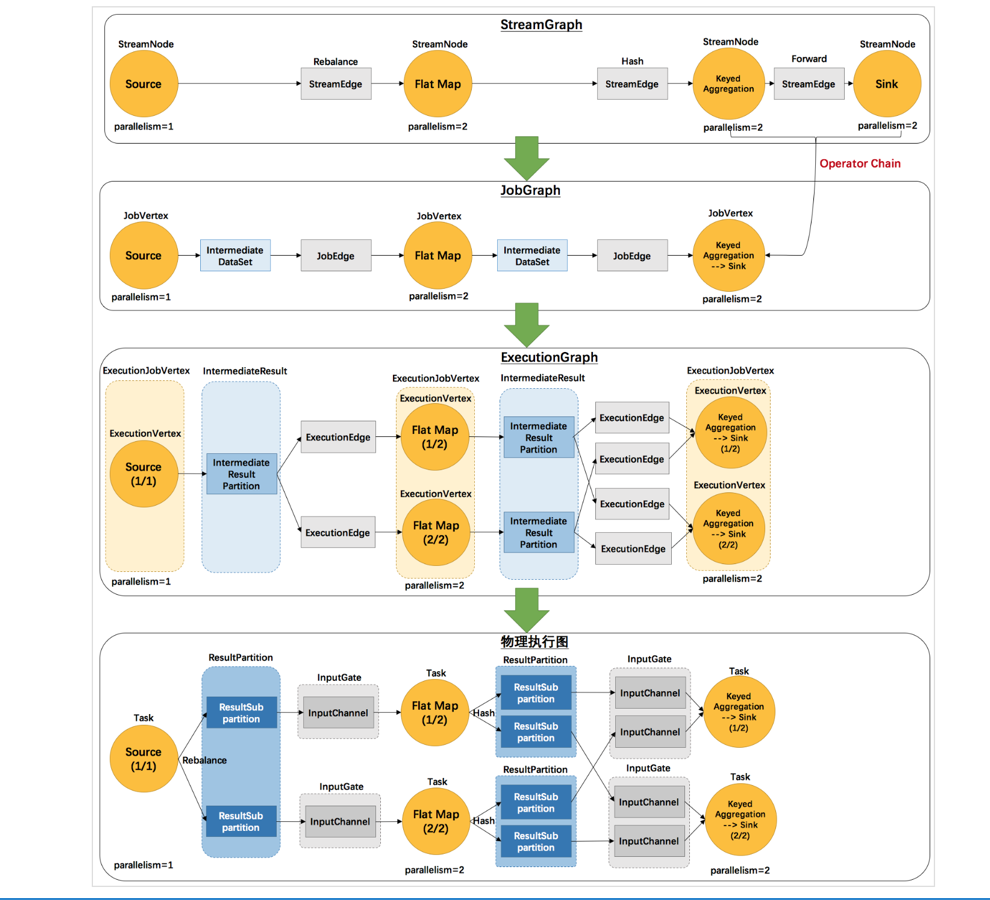
这里对一些名词进行简单的解释。
-
StreamGraph:根据用户通过 Stream API 编写的代码生成的最初的图。
-
-
StreamNode:用来代表 operator 的类,并具有所有相关的属性,如并发度、入边和出边等。
-
StreamEdge:表示连接两个StreamNode的边。
-
-
JobGraph:StreamGraph经过优化后生成了 JobGraph,提交给 JobManager 的数据结构。
-
-
JobVertex:经过优化后符合条件的多个StreamNode可能会chain在一起生成一个JobVertex,即一个JobVertex包含一个或多个operator,JobVertex的输入是JobEdge,输出是IntermediateDataSet。
-
IntermediateDataSet:表示JobVertex的输出,即经过operator处理产生的数据集。producer是JobVertex,consumer是JobEdge。
-
JobEdge:代表了job graph中的一条数据传输通道。source 是 IntermediateDataSet,target 是 JobVertex。即数据通过JobEdge由IntermediateDataSet传递给目标JobVertex。
-
-
ExecutionGraph:JobManager 根据 JobGraph 生成ExecutionGraph。ExecutionGraph是JobGraph的并行化版本,是调度层最核心的数据结构。
-
-
ExecutionJobVertex:和JobGraph中的JobVertex一一对应。每一个ExecutionJobVertex都有和并发度一样多的 ExecutionVertex。
-
ExecutionVertex:表示ExecutionJobVertex的其中一个并发子任务,输入是ExecutionEdge,输出是IntermediateResultPartition。
-
IntermediateResult:和JobGraph中的IntermediateDataSet一一对应。一个IntermediateResult包含多个IntermediateResultPartition,其个数等于该operator的并发度。
-
IntermediateResultPartition:表示ExecutionVertex的一个输出分区,producer是ExecutionVertex,consumer是若干个ExecutionEdge。
-
ExecutionEdge:表示ExecutionVertex的输入,source是IntermediateResultPartition,target是ExecutionVertex。source和target都只能是一个。
-
Execution:是执行一个 ExecutionVertex 的一次尝试。当发生故障或者数据需要重算的情况下 ExecutionVertex 可能会有多个 ExecutionAttemptID。一个 Execution 通过 ExecutionAttemptID 来唯一标识。JM和TM之间关于 task 的部署和 task status 的更新都是通过 ExecutionAttemptID 来确定消息接受者。
-
-
物理执行图:JobManager 根据 ExecutionGraph 对 Job 进行调度后,在各个TaskManager 上部署 Task 后形成的“图”,并不是一个具体的数据结构。
-
-
Task:Execution被调度后在分配的 TaskManager 中启动对应的 Task。Task 包裹了具有用户执行逻辑的 operator。
-
ResultPartition:代表由一个Task的生成的数据,和ExecutionGraph中的IntermediateResultPartition一一对应。
-
ResultSubpartition:是ResultPartition的一个子分区。每个ResultPartition包含多个ResultSubpartition,其数目要由下游消费 Task 数和 DistributionPattern 来决定。
-
InputGate:代表Task的输入封装,和JobGraph中JobEdge一一对应。每个InputGate消费了一个或多个的ResultPartition。
-
InputChannel:每个InputGate会包含一个以上的InputChannel,和ExecutionGraph中的ExecutionEdge一一对应,也和ResultSubpartition一对一地相连,即一个InputChannel接收一个ResultSubpartition的输出。
-
那么 Flink 为什么要设计这4张图呢,其目的是什么呢?Spark 中也有多张图,数据依赖图以及物理执行的DAG。其目的都是一样的,就是解耦,每张图各司其职,每张图对应了 Job 不同的阶段,更方便做该阶段的事情。我们给出更完整的 Flink Graph 的层次图。
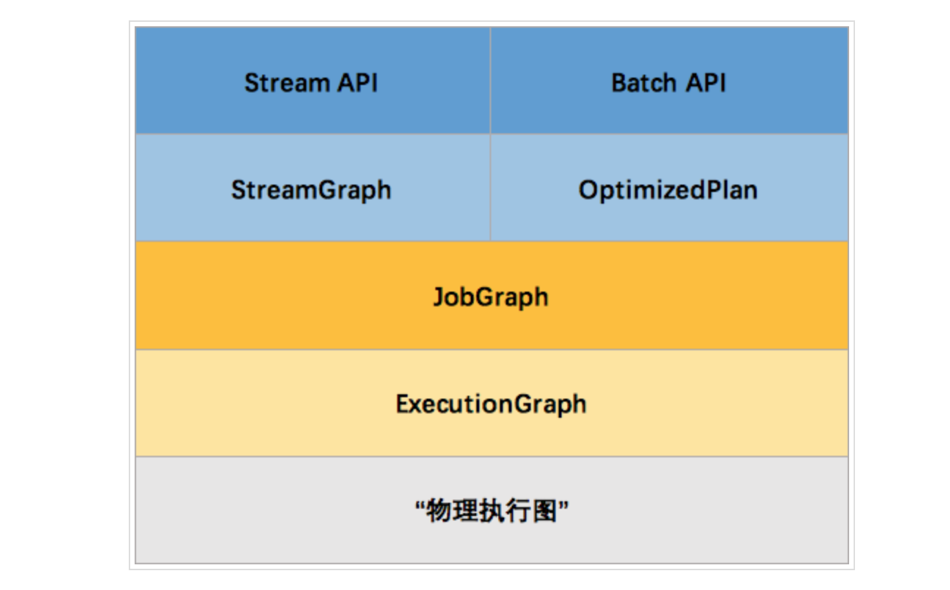
首先我们看到,JobGraph 之上除了 StreamGraph 还有 OptimizedPlan。OptimizedPlan 是由 Batch API 转换而来的。StreamGraph 是由 Stream API 转换而来的。为什么 API 不直接转换成 JobGraph?因为,Batch 和 Stream 的图结构和优化方法有很大的区别,比如 Batch 有很多执行前的预分析用来优化图的执行,而这种优化并不普适于 Stream,所以通过 OptimizedPlan 来做 Batch 的优化会更方便和清晰,也不会影响 Stream。JobGraph 的责任就是统一 Batch 和 Stream 的图,用来描述清楚一个拓扑图的结构,并且做了 chaining 的优化,chaining 是普适于 Batch 和 Stream 的,所以在这一层做掉。ExecutionGraph 的责任是方便调度和各个 tasks 状态的监控和跟踪,所以 ExecutionGraph 是并行化的 JobGraph。而“物理执行图”就是最终分布式在各个机器上运行着的tasks了。所以可以看到,这种解耦方式极大地方便了我们在各个层所做的工作,各个层之间是相互隔离的。
参考资料:http://wuchong.me/blog/2016/05/03/flink-internals-overview/
Task Slots and Resources
每个Worker(TaskManager)都是一个独立的JVM进程,它通过Task Slot(任务槽)来控制能执行的线程数,且每个TaskManager至少有一个slot。有几个slot即平分该JVM内存。注意,这里指的是内存隔离,不会发生CPU隔离。
同一JVM种的任务共享TCP连接(通过多路复用)和心跳消息。它们也可能共享数据集和数据结构,从而减少每个任务的开销。
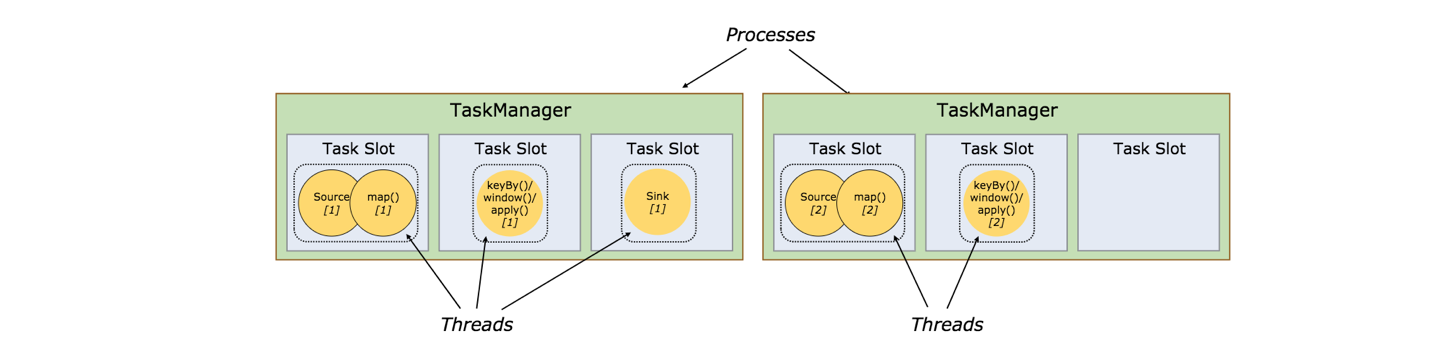
默认,如果subtask是来自相同job,即使不是相同的task,Flink也允许subtask共享slot。结果是,一个slot可能包含该job的整个pipeline。允许slot共享有两个好处:
-
Flink集群确实需要许多task slots来让Job达到最高的并行度。不需要计算一个程序总共包含多少个task。
-
更容易获得更好的资源利用。如果没有slot共享,非密集型的source/map()的subtask将阻塞跟密集型的window的subtask一样多的占用资源。而如果有slot共享,基本的并发度通过完整地利用共享的slot资源将获得2到6倍的提升,同时仍然保证每一个TaskManager会在任务繁重的subtask之间进行合理的slot共享。
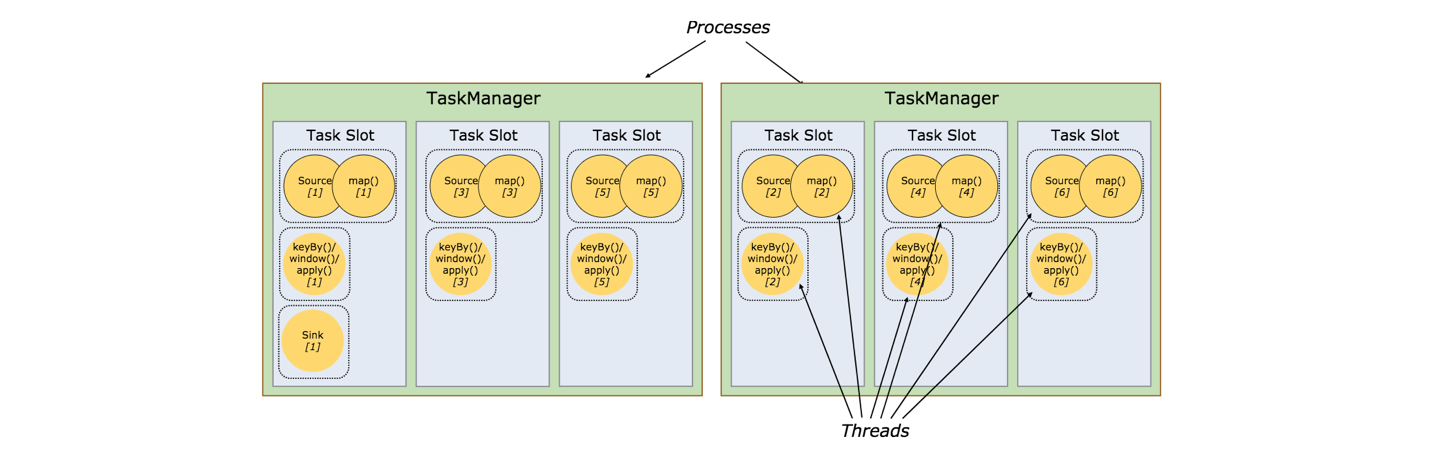
slot共享行为可以通过API来控制,以防止不合理的共享。这个机制称之为resource groups,它定义了subtask可能共享的slot是什么资源。
作为一个约定俗成的规则,task slot推荐的默认值是CPU的核数。基于超线程技术,每个slot占用两个或者更多的实际线程上下文。
参考文档
https://ci.apache.org/projects/flink/flink-docs-release-1.4/
![流式计算框架容错和高性能如何兼得[转]](/wp-content/uploads/2018/08/flink-daishu_2018.08.02.png)


