
- A+
一、功能概述
Calcite是Apache孵化的一个项目,主要作用是提供标准的SQL语言查询底层各种数据源的一个工具,注意它不是个服务,一般常用作集成到某些框架里,比如Apache Drill、Apache Hive、Apache Kylin、Apache Phoenix、Apache Samza、Apache Flink、Lingual等。
Calcite采用的是业界大数据查询框架的一种通用思路,它的目标是“one size fits all(一种方案适应所有需求场景)”,希望能为不同计算平台和数据源提供统一的查询引擎。上层尽量简单的封装请求,所以它定义为标准的SQL,中间通过构建JDBC或ODBC来访问“Calcite数据库”(其实Calcite并没有数据库,需要我们在代码里告诉Calcite,虚拟出来的表是什么、字段是什么、字段类型是什么等,整体抽象为一个个Schema,对于我们来说就查Calcite虚拟出来东西,不用关心底层真正对接了哪些数据源),底层通过定义各种adapter,来对接不同的查询和存储引擎(比如es、habse、redis、mysql,甚至是CSV、HDFS等),这也就决定了它其实没有真正的“物理执行计划”(后面会提到执行计划相关)。
假设我们不参与(ScannableTable)Calcite的查询过程,即不做SQL解析,不做优化,只要把它接入进来,实际Calcite是可以工作的,无非就是可能会有扫全表、数据全部加载到内存里等问题,所以实际中我们可能会参与全部(Translatable)或部分工作(FilterableTable),覆盖Calcite的一些执行计划或过滤条件,让它能更高效的工作。
值得一提的是,Calcite支持异构数据源查询,比如数据存在es和mysql,可以通过写sql join之类的操作,让calcite分别先从不同的数据源查询数据,然后再在内存里进行合并计算;另外,它本身提供了许多优化规则,也支持我们自定义优化规则,来优化整个查询。
二、技术特性
- 支持标准SQL语言;
- 独立于编程语言和数据源,可以支持不同的前端和后端
- 支持关系代数、可定制的逻辑规划规则和基于成本模型优化的查询引擎
- 支持物化视图(materialized view)的管理(创建、丢弃、持久化和自动识别)
-
基于物化视图的Lattice和Tile机制,以应用于OLAP分析;
支持对流数据的查询
###补充特性###
- 跨数据源查询
-
Calcite本身会缓存Schema、Function等信息(我们目前没用到,自己在内存里缓存的)
支持复合指标计算(a+b as c)、常用聚合函数(sum、count、distinct)、sort、group by、join、limit等 - 架构比较精简,利用Calcite写几百行代码就可以实现一个SQL查询方案;
- 灵活绑定优化规则,对于一个条件,我们可以自定义多个优化规则,只要命中,可以根据不同的规则多次优化同一个查询条件
三、3种Table
1. ScannableTable
a simple implementation of Table, using the ScannableTable interface, that enumerates all rows directly
这种方式基本不会用,原因是查询数据库的时候没有任何条件限制,默认会先把全部数据拉到内存,然后再根据filter条件在内存中过滤。
使用方式:实现Enumerable scan(DataContext root);,该函数返回Enumerable对象,通过该对象可以一行行的获取这个Table的全部数据。
2. FilterableTable
a more advanced implementation that implements FilterableTable, and can filter out rows according to simple predicates
初级用法,我们能拿到filter条件,即能再查询底层DB时进行一部分的数据过滤,一般开始介入calcite可以用这种方式(translatable方式学习成本较高)。
使用方式:实现Enumerable scan(DataContext root, List filters )。
在scan的源码定义中: 
如果当前类型的“表”能够支持我们自己写代码优化这个过滤器,那么执行完自定义优化器,可以把该过滤条件从集合中移除,否则,就让calcite来过滤,简言之就是,如果我们不处理Listfilters ,Calcite也会根据自己的规则在内存中过滤,无非就是对于查询引擎来说查的数据多了,但如果我们可以写查询引擎支持的过滤器(比如写一些hbase、es的filter),这样在查的时候引擎本身就能先过滤掉多余数据,更加优化。提示,即使走了我们的查询过滤条件,可以再让calcite帮我们过滤一次,比较灵活。demo如下: 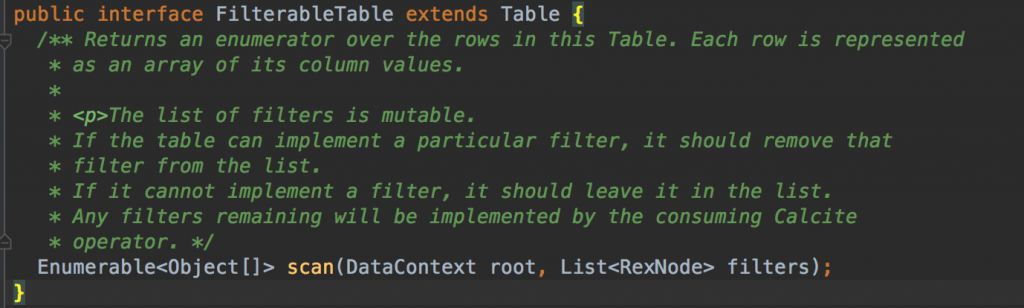
3. TranslatableTable
advanced implementation of Table, using TranslatableTable, that translates to relational operators using planner rules.
高阶用法,有些查询用上面的方式都支持不了或支持的不好,比如join、聚合、或对于select的字段筛选等,需要用这种方式来支持,好处是可以支持更全的功能,代价是所有的解析都要自己写,“承上启下”,上面解析sql的各个部件,下面要根据不同的DB(es\mysql\drudi..)来写不同的语法查询。
当使用ScannableTable的时候,我们只需要实现函数Enumerable

2019-09-06 10:40 沙发
Apache Calcite目前不支持Oracle Hint语句的解。Apache JSqlParser支持hint解析,但某些函数如:SESSION函数不支持
2020-12-29 16:49 板凳
不行