
- A+
基本功能
Apache Flink是一个面向分布式数据流处理和批量数据处理的开源计算平台,它能够基于同一个Flink运行时,提供支持流处理和批处理两种类型应用的功能。
现有的开源计算方案,会把流处理和批处理作为两种不同的应用类型,因为它们所提供的SLA(Service-Level-Aggreement)是完全不相同的:流处理一般需要支持低延迟、Exactly-once保证,而批处理需要支持高吞吐、高效处理。
Flink从另一个视角看待流处理和批处理,将二者统一起来:Flink是完全支持流处理,也就是说作为流处理看待时输入数据流是无界的;批处理被作为一种特殊的流处理,只是它的输入数据流被定义为有界的。
主要特性
-
支持高吞吐、低延迟、高性能的流处理
-
支持带有事件时间的窗口(Window)操作【Flink亮点】
-
支持有状态计算的Exactly-once语义
-
支持高度灵活的窗口(Window)操作,支持基于time、count、session,以及data-driven的窗口操作
-
支持具有Backpressure功能的持续流模型
-
支持基于轻量级分布式快照(Snapshot)实现的容错【Flink亮点】
-
一个运行时同时支持Batch on Streaming处理和Streaming处理
-
Flink在JVM内部实现了自己的内存管理
-
支持迭代计算
-
支持程序自动优化:避免特定情况下Shuffle、排序等昂贵操作,中间结果有必要进行缓存
-
支持消息乱序处理【Flink亮点】
基本架构
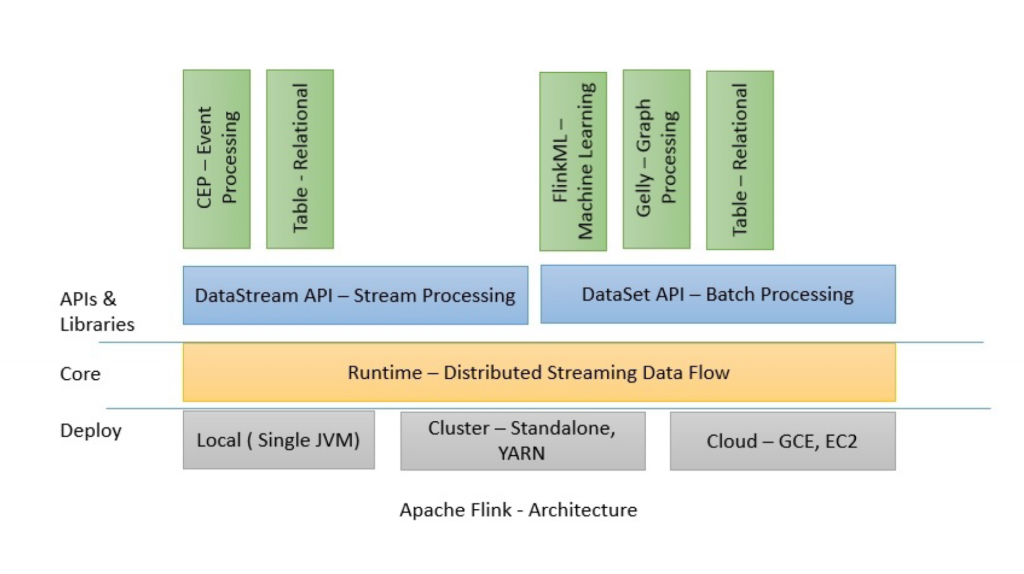
-
Flink可以运行在本地计算机上,YARN群集中或云上。
-
Runtime是Flink的核心数据处理引擎,通过JobGraph形式的API接收程序。 JobGraph是一个简单的并行数据流(Dataflow),包含一组产生和使用数据流的任务。
-
DataStream(流计算)和DataSet(Batch计算) API是程序员可以用来定义Job的接口。 JobGraphs是在编译程序时由这些API生成的。一旦编译完成,DataSet API允许优化器生成最佳执行计划,而DataStream API则使用流生成来实现高效的执行计划,然后根据部署模型将优化的JobGraph提交给执行者。DataSet API使用optimizer来决定针对程序的优化方法,而DataStream API则使用stream builder来完成该任务。
-
Flink附随了一些产生DataSet或DataStream API程序的的类库和API:处理逻辑表查询的Table,机器学习的FlinkML,图像处理的Gelly,复杂事件处理的CEP。
![流式计算框架容错和高性能如何兼得[转]](/wp-content/uploads/2018/08/flink-daishu_2018.08.02.png)


