
优化对于HBase是必不可少的,庞大的数据集可能因为某个简单的改动让HBase集群的性能提升数倍。 1. 表的设计 1.1 提前创建多个Region 默认情况下,在创建HBase表的时候会自动创建一个Region分区,当导入数据的时候...
 HBase
HBase
HBase
HBase
 HBase
HBase
 HBase
HBase
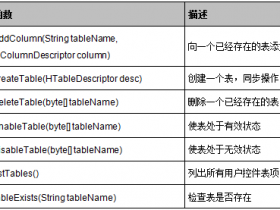 HBase
HBase
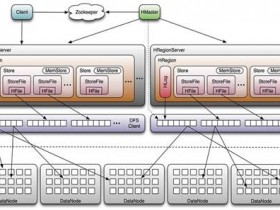 HBase
HBase
 HBase
HBase
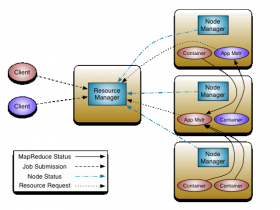 Hadoop
Hadoop
 Flink
Flink
