- A+
所属分类:HBase
关于Hbase的基础介绍网上已经一大堆了,随便一搜即可知道它的一些描述“列存储”、“BigTable”之类的,在这里直接总结一些基本特性。
1. 基本特性
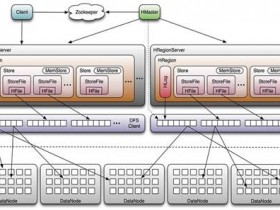
(1) Hbase基于HDFS(故Hbase和DFS有关,和Yarn无关,如果单纯的操作Hbase,只启动dfs-start.sh即可);
(2) Hbase支持简单查询,不支持join等复杂查询,不支持复杂事物(支持行级事物,即行原子性操作,不论有多少列,一次性查出);
(3) Hbase支持数据类型:byte[](这也就是我们通过hbase shell看到表里存的内容我们不能直接看懂的原因);
(4) 与Hadoop一样,Hbase目标主要依靠横向扩展,通过不断增加廉价的商用服务器,来增加计算和存储能力(即只要扩Datanode和Regionserver即可)。
2. 关于表(Table)
(1) 大:一个表可以有上亿行,百万列;
(2) 面向列:面向列(族)的存储和权限控制,列(族)独立检索;
(3) 稀疏:对于空(null)列,不占空间。
3. 关于行键(Rowkey)
(1) Rowkey是检索主键,查询行时只有三种方式:Get 单个Rowkey;通过Rowkey所在的Region;Scan整张表。
(2) Rowkey最大长度64kb,实际应用一般为10-100bytes,在Hbase底层,Rowkey以字节数组的形式保存。
(3) Rowkey底层存储按照字典序存储,故在使用时要注意Rowkey的设计。
字典序:1,10,100,11,12,13,14,2,20...
所以要保持自然的整形排序,需要用0作左填充。
4. 关于列族(Column Family)
(1) 列族是属于Schema的一部分,所以建表要声明(而列不用)。
(2) 实际应用可以基于列族来做权限控制,指定某些应用可以读、某些可写等。
5. 关于时间戳(Timestamp)
HBase中通过row和columns确定的为一个存贮单元称为cell。每个 cell都保存着同一份数据的多个版本。版本通过时间戳来索引。时间戳的类型是 64位整型。时间戳可以由hbase(在数据写入时自动 )赋值,此时时间戳是精确到毫秒的当前系统时间。时间戳也可以由客户显式赋值。如果应用程序要避免数据版本冲突,就必须自己生成具有唯一性的时间戳。每个 cell中,不同版本的数据按照时间倒序排序,即最新的数据排在最前面。
为了避免数据存在过多版本造成的的管理 (包括存贮和索引)负担,hbase提供了两种数据版本回收方式。一是保存数据的最后n个版本,二是保存最近一段时间内的版本(比如最近七天)。用户可以针对每个列族进行设置。
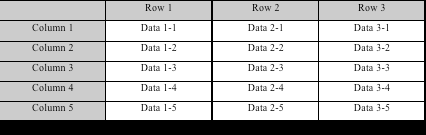
1.6 行存储和列存储的对比
(1) 行存储:
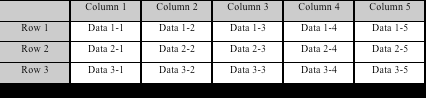

(2) 列存储: