- A+
这篇文章主要介绍了在本地虚拟机环境(VMware)中搭建最基础的Hadoop集群的过程,包括准备工作、搭建虚拟机和系统、Hadoop集群安装配置、运行MapReduce实例以及整个过程中可能会碰到的一些问题,比较详细,希望对初学者有帮助。
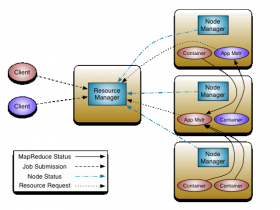
【架构介绍】
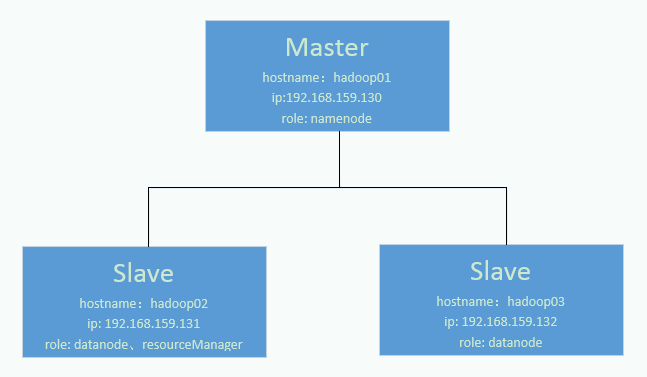
【准备工作】
2. CentOS:CentOS-6.7-x86_64-bin-DVD1.iso (下载:http://pan.baidu.com/s/1o7xYgGE )
或Ubuntu(以CentOS为例,一般生产环境用的是CentOS)
3. 本地机器配置:

4. Hadoop
(1)版本2.7.1
(2)下载地址:http://www.apache.org/dyn/closer.cgi/hadoop/common/hadoop-2.7.1/hadoop-2.7.1.tar.gz

5. JDK
(1)版本1.7.9
(2)下载地址:http://www.oracle.com/technetwork/java/javase/downloads/jdk7-downloads-1880260.html
【正式安装】
1. 安装VMware、安装Centos
这里就不截图了,详细安装过程百度一下或参考:http://blog.itpub.net/26230597/viewspace-1255651/
注意事项:
(1)安装顺序:虚拟机节点先安装一个,完成基本配置后通过“克隆”的方式复制另外两个,这样既可以保证环境统一,又比较方便。
(2)网络连接:选择桥接方式。建议最好手动把IP地址固定下来,避免动态分配的时候错乱。
(3)防火墙:关闭防火墙,避免出现后面不必要的麻烦,chkconfig iptables off。
(4)内存分配:hadoop01 1024M,hadoop02 1024M(因为有resourcemanager),hadoop03 512M。
2. 安装vim和ssh
(1)安装vim
yum -y install vim
PS:可以先测试一下有没有自带。
(2)安装ssh
yum -y install ssh
PS:可以通过service ssh status 查看ssh状态。
3. 修改hostname
vi /etc/sysconfig/network
修改HOSTNAME的值为hadoop01。
4. 修改hosts
vi /etc/hosts
192.168.159.130 hadoop01
192.168.159.131 hadoop02
192.168.159.132 hadoop03
5. 安装jdk
(1)上传:
用工具winscp上传jdk包至目录/usr/lib/java,winscp配置时端口默认22。
(2)解压:
tar -zxvf jdk1.7.0_79.tar
(3)修改环境变量:
vim ~/.bashrc
在最下面添加:
export JAVA_HOME = /usr/lib/java/jdk1.7.0_79
export PATH = $JAVA_HOME/bin:$PATH
修改完后,让配置文件生效:
source ~/.bashrc
6. 安装hadoop
(1)上传:
用工具winscp上传hadoop包至目录/opt。
(2)解压:
tar -zxvf hadoop2.7.1.tar
重命名:
mv hadoop-2.7.1 hadoop
(3)修改环境变量
vim ~/.bashrc
在最下面添加:
export HADOOP_HOME = /opt/hadoop
export PATH = $JAVA_HOme/bin:$HADOOP_HOME/bin:$PATH
修改完后,让配置文件生效:
source ~/.bashrc
7. 克隆
通过VMware克隆另外两个节点出来,参照4中的配置修改IP地址和hostname。
6. 配置ssh,实现免密码登录
(1)在三台机器上分别执行如下命令,一路按回车即可。
ssh-keygen -t rsa
authorized_keys,已认证的keys(如果没有,可自建)id_rsa,私钥
id_rsa.pub,公钥
把三台机器~/.ssh/id_rsa.pub中的内容拷贝到hadoop01的authorized_keys文件里,然后在hadoop01上scp到各台机器上相同目录下,命令:
scp authorized_keys root@192.168.159.131:~/.ssh
scp authorized_keys root@192.168.159.132:~/.ssh
格式: scp authorized_keys 远程主机用户名@远程主机名或ip:存放路径。
建议:最好是三台都互相免密码登录,不只是从master到另外两台。
ssh hadoop02
看是否不用密码就可以登录过去,直接进入,表示成功。
8. 修改hadoop基本配置
路径:/opt/hadoop/etc/conf/
(1)修改 core-site.xml
在<configuration></configuration>里添加如下内容:
<property>
<name>hadoop.tmp.dir</name>
<value>/tmp</value>
</property>
<!--fs.defaultFS 客户端连接HDFS时,默认的路径前缀 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop01:9000</value>
</property>
(2)修改hadoop-env.sh
修改或添加如下内容:
export HADOOP_CONF_DIR=/opt/hadoop/etc/hadoop
export JAVA_HOME=/usr/lib/java/jdk1.7.0_79
export HADOOP_HOME=/opt/hadoop
export PATH=$HADOOP_HOME/bin:$PATH
(3)修改 hdfs-site.xml
在<configuration></configuration>里添加如下内容:
<property>
<name>dfs.name.dir</name>
<value>/data/dfs/name</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property><!--datanode配置-->
<property>
<name>dfs.data.dir</name>
<value>/data/dfs/data</value>
</property>
(4)cp mapred-site.xml.template mapred-site.xml
然后在mapred-site.xml的<configuration></configuration>里添加如下内容:
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapred.job.tracker</name>
<value>hadoop01:9001</value>
</property>
<property>
<name>mapreduce.job.user.classpath.first</name>
<value>false</value>
</property>
<property>
<name>mapreduce.task.timeout</name>
<value>900000</value>
</property>
<property>
<name>mapred.map.tasks</name>
<value>5</value>
</property>
<property>
<name>mapred.reduce.tasks</name>
<value>10</value>
</property>
(5)修改slaves
加入如下内容:
hadoop02
hadoop03
(6)创建masters文件
vim masters
并加入如下内容:
hadoop01
(7)修改yarn-site.xml
在<configuration></configuration>里添加如下内容:
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property><property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property><property>
<name>yarn.nodemanager.local-dirs</name>
<value>/data/yarn/local</value>
<description>the local directories used by thenodemanager</description>
</property><property>
<name>yarn.resourcemanager.address</name>
<value>hadoop02:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>hadoop02:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>hadoop02:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>hadoop02:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>hadoop02:8088</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.CapacityScheduler</value>
</property>
(8)yarn-env.sh
修改第23行:
# export JAVA_HOME=/home/y/libexec/jdk1.6.0/
改成
export JAVA_HOME=/usr/lib/java/jdk1.7.0_79
9. 同步hadoop配置到另外两台机器
scp /opt/hadoop/etc/hadoop/* hadoop02:/opt/hadoop/etc/hadoop/
scp /opt/hadoop/etc/hadoop/* hadoop03:/opt/hadoop/etc/hadoop/
至此,配置安装配置就完成了。
【启动测试】
1. 在hadoop02上执行
hadoop namenode -format
sh /opt/hadoop/sbin/start-all.sh
2. "jps"命令查看进程
(1)hadoop01上
1243 namenode
(2)hadoop02上
2830 resourcemanager
1802 nodemanager
2901 datanode
(3)hadoop03上
1626 datanode
2018 nodemanager
3. 测试hdfs
创建:hadoop fs -mkdir /workspace
查看:hadoop fs -ls /
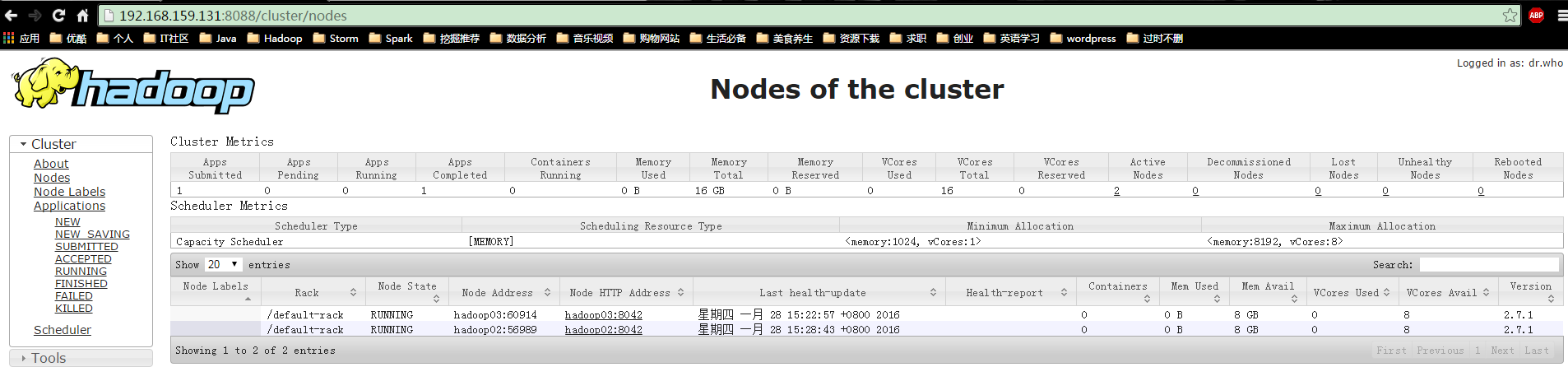
4. 通过UI查看
http://192.168.159.130:8088/cluster/nodes
【运行MapReduce】
1. 准备数据
在本地目录创建wordcount.txt文件,并随便输入写英文,如:
aa bb cc dd
2. 上传文件
hadoop fs -put ./wordcount.txt /workspace
3. 执行命令
hadoop jar /opt/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.1.jar wordcount /workspace/wordcount.txt /outpath
4. UI查看任务
http://192.168.159.130:8088/cluster/app/RUNNING
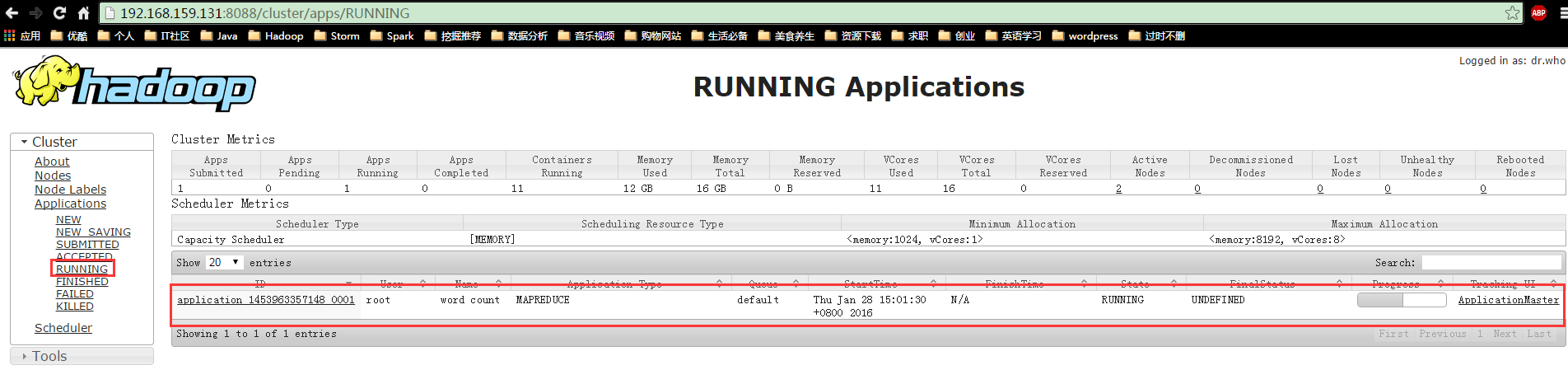
5. 查看结果
hadoop fs -cat /outpath/*
aa 1
bb 1
cc 1
dd 1
【遇到的问题】
1. 拒绝连接
问题描述:在启动和运行任务时报连接拒绝等问题。
解决方案:检查防火墙是否已关闭。
2. resourcemanager起动失败
问题描述:启动集群时,其他进程都正常,只有resourcemanager启动失败,或只启动短暂几秒钟后失败。
解决方案:通过hadoop02机器(即resourcemanager所在机器)执行sh start-all.sh启动集群。
3. 执行start-all.sh时出现异常
问题描述:启动集群时,报错:Error:Cannot find configuration directory:/etc/hadoop
解决方案:在 hadoop-env.sh 配置文件中将 export HADOOP_CONF_DIR=${HADOOP_CONF_DIR:-"etc/hadoop"}替换成 export HADOOP_CONF_DIR=/usr/hadoop-2.6.0/etc/hadoop修改完后运行 source hadoop-env.sh 让其立即生效!
4. 运行Wordcount报错
问题描述:跑自带WordCount时候报mapreduce_shuffle does not exist。
解决方案:在yarn-site.xml中加如下配置
5. 运行Wordcount一段时间后报错
问题描述:hadoop org.apache.hadoop.yarn.exceptions.YarnException: Unauthorized request to start container
解决方案:百度说是集群的时间不同步,解决方法参考:
http://www.chinadmd.com/file/tixiarput3eweszaceuzpttc_1.html
http://www.aboutyun.com/thread-11397-1-2.html
http://www.linuxde.net/2013/02/12232.html
【写在最后】
第一次写这篇文章时,各种排版神马的费老劲了,悲剧的是,第二天突然Mysql引擎InnoDB不知为何损坏了,尝试了很多方案也没找到好的方法,也可能是技术太渣了,最后只恢复了大部分数据,又咬牙重写了一次,真正体会到了备份的重要性了,各位父老乡亲们以后一定要引以为戒啊,共勉!