- A+
Storm已经火了一段时间了,对于实时分析确实得到的市场的认可,今天从零开始研究一下Storm到底怎么玩儿,同时把过程中遇到的问题及收获记录下来,我始终坚信在互联网时代,分享是一种美德。我不喜欢废话连篇的空理论,这对于作者和读者都可以节约时间成本,所以省去了许多不必要的过程,只记录重点内容。
学技术我一直比较喜欢的一种方式是“先运行再理解”,先把自带的demo跑一遍,知道是个神马玩意儿再去理解它的原理和代码,这样的好处是能整体把握,有助于快速理解。
1. 下载Demo
Storm官网下载的包里有个目录“examples”,下面有工程"storm-starter",里面的类很多,而且自带的WordCount例子需要Python环境神马的,还不能直接跑,太烦了。所以就做了个提取,pom.xml文件已配置好,不想关的内容都已剔除,只剩下WordCount的两个类,下载地址: http://pan.baidu.com/s/1bnGYNlt
2. 本地运行
Storm有两种运行模式,本地和集群。这里我们在eclipse 中运行即可,默认的jar包里有一个叫“LocalCluster”的类可以在本地支持运行。不管三七二十一,先找到WordCountTopology.java类run,就可以看到如下结果:
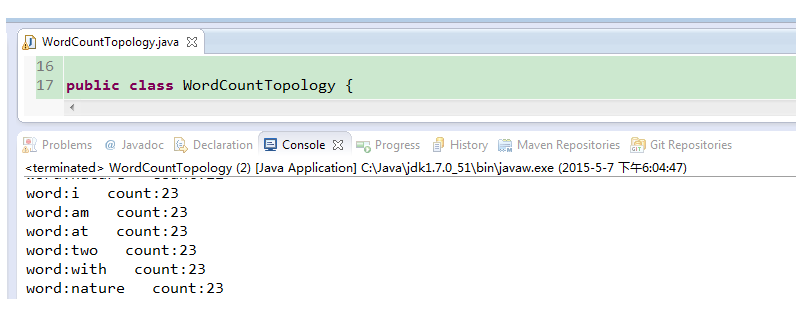
对于程序员来说执行成功就是最大的胜利,结果和MapReduce的效果一样,但原理不同,下面一一道来。
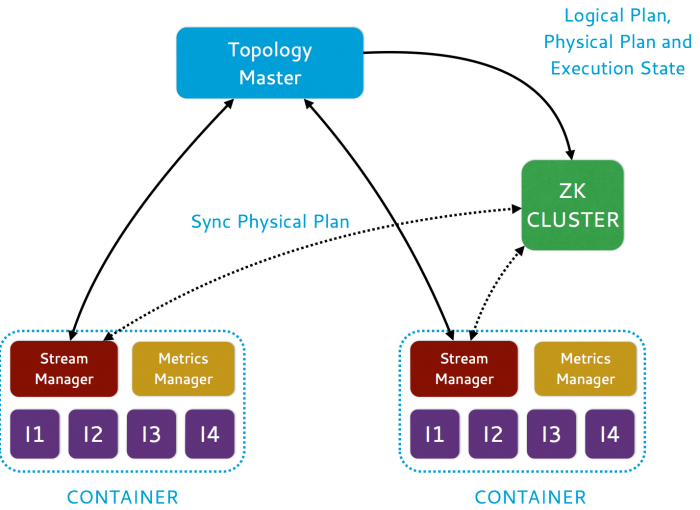
3. Storm 的架构图
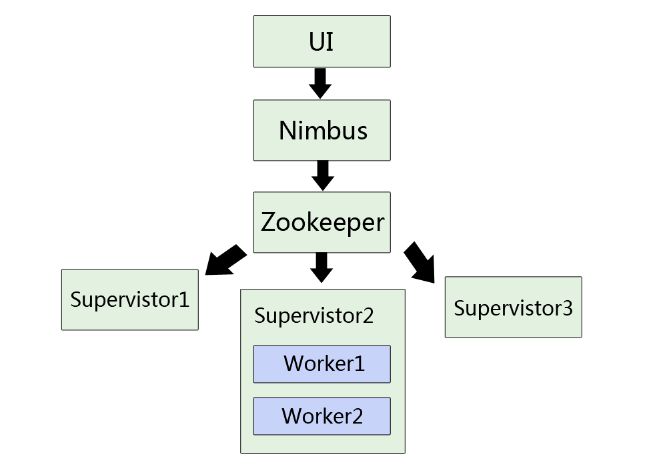
(1) 理解Nimbus、Zookeeper、Supervistor的位置关系
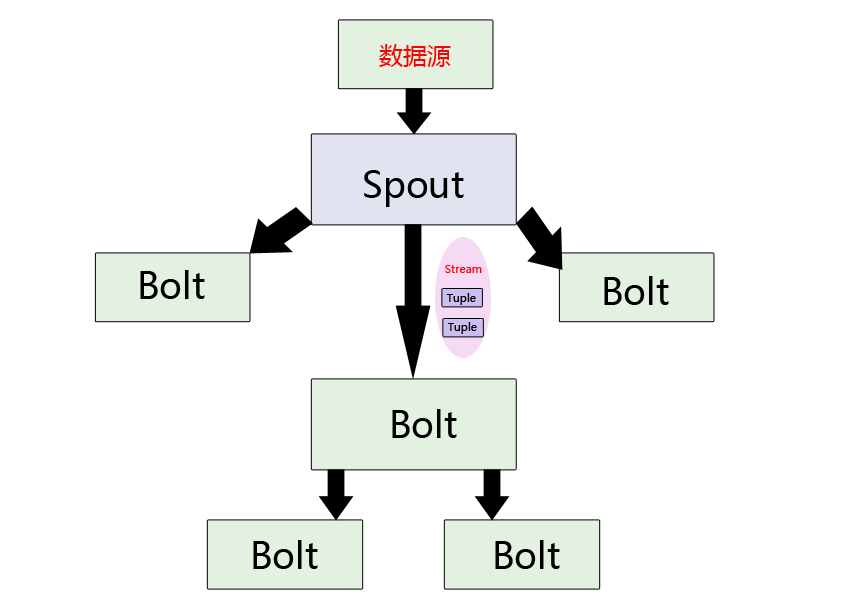
(2) 理解Spout、Bolt、Tuple的位置关系
4. Storm 核心概念解释
(1) Nimbus:
Nimbus在整个集群中唯一存在,相当于master角色,负责把Jar包等资源分发给各个工作的机器,并对其状态进行监控。
(2) Supervisor
监听分配给它那台机器的工作,根据需要启动/关闭工作进程Worker。每一个要运行Storm的机器上都要部署一个,并且按照机器的配置设定上面分配的槽位数。
(3) Zookeeper
Storm重点依赖的外部资源。Nimbus和Supervisor甚至实际运行的Worker都是把心跳保存在Zookeeper上的,Nimbus也是根据Zookeerper上的心跳和任务运行状况,进行调度和任务分配的。两者之间的调度器。
(4) Spout
这是整个程序中数据的入口,在一个topology中产生源数据流的组件。通常情况下spout会从外部数据源中读取数据,然后转换为topology内部的源数据。Spout是一个主动的角色,其接口中有个nextTuple()函数,storm框架会不停地调用此函数,用户只要在其中生成源数据即可。
(5) Bolt
在一个topology中接受数据然后执行处理的组件。Bolt可以执行过滤、函数操作、合并、写数据库等任何操作。Bolt是一个被动的角色,其接口中有个execute(Tuple input)函数,在接受到消息后会调用此函数,用户可以在其中执行自己想要的操作。
(6) Topology
storm中运行的一个实时应用程序,因为各个组件间的消息流动形成逻辑上的一个拓扑结构。拓扑(Topology)可以理解为是storm执行任务的单位。
(7) Worker
顾名思义就是干活的,它是具体处理组建逻辑的进程。
(8) Task
和上面的worker联系起来理解,不再与物理进程对应,是处理任务的线程。
(9) Stream
Storm处理的就是流式数据,它的“流”叫Tuple,源源不断的Tuple就组成了Stream。
(10) Tuple
一次消息传递的基本单元。本来应该是一个key-value的map,但是由于各个组件间传递的tuple的字段名称已经事先定义好,所以tuple中只要按序填入各个value就行了,所以就是一个value list。
(11) Acker
可以理解为买东西快递的“签字”,Spout把数据传给它的儿子Bolt、孙子Bolt,需要让它们告诉Spout“我收到货了”。
5. WordCount代码剖析
(1) WordCountTopology类
package net.circleblog.dc.cloud.wordcount;
import java.util.HashMap;
import java.util.Map;
import backtype.storm.Config;
import backtype.storm.LocalCluster;
import backtype.storm.StormSubmitter;
import backtype.storm.topology.BasicOutputCollector;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.topology.TopologyBuilder;
import backtype.storm.topology.base.BaseBasicBolt;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Tuple;
import backtype.storm.tuple.Values;
//WordCount的执行主类
public class WordCountTopology {
// blot1用来把输入的内容分成独立单词,例如:"I think you are right"拆成 “I" "think" "you" "are" "wrong"
public static class SplitSentence extends BaseBasicBolt { //BaseBasicBolt是自带的基类
public void execute(Tuple input, BasicOutputCollector collector) {
try {
String msg = input.getString(0);
// System.out.println(msg + "-------------------");
if (msg != null) {
String[] s = msg.split(" ");
for (String string : s) {
collector.emit(new Values(string));
// System.out.println(string + "+++++++++++++");
}
}
} catch (Exception e) {
e.printStackTrace();
}
}
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word"));
}
}
// bolt2用来处理bolt1的结果
public static class WordCount extends BaseBasicBolt {
Map<String, Integer> counts = new HashMap<String, Integer>();
public void execute(Tuple tuple, BasicOutputCollector collector) {
String word = tuple.getString(0);
Integer count = counts.get(word);
if (count == null)
count = 0;
count++;
counts.put(word, count);
System.out.println("word:" + word + " count:" + count);
// collector.emit(new Values(word, count));
}
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word", "count"));
}
}
//main主方法
public static void main(String[] args) throws Exception {
TopologyBuilder builder = new TopologyBuilder(); //定义一个拓扑
builder.setSpout("spout", new RandomSentenceSpout(), 1); //定义数据入口spout
/*
* 根据业务需要可以设置任意数量的bolt,因为是流式计算,可以理解为“数据加工接龙”,前一个bolt处理好的数据传给后一个处理。
* 设置多个bolt的好处是每个bolt可以多线程并发执行,提高效率
*/
builder.setBolt("split", new SplitSentence(), 1).shuffleGrouping("spout");
builder.setBolt("count", new WordCount(), 1).fieldsGrouping("split", new Fields("word"));
Config conf = new Config();
conf.setDebug(false);// 值为true的时候可以打印更多详细的信息,否则只打印执行结果
if (args != null && args.length > 0) {
conf.setNumWorkers(3); //设置worker的数量,根据集群的条件来设,本地跑的话无所谓了
StormSubmitter.submitTopology(args[0], conf, builder.createTopology()); //提交拓扑
} else {
conf.setMaxTaskParallelism(1);
LocalCluster cluster = new LocalCluster(); //启动本地模拟集群
cluster.submitTopology("word-count", conf, builder.createTopology());
Thread.sleep(10000);
cluster.shutdown();
}
}
}
(2) RandomSentenceSpout类
package net.circleblog.dc.cloud.wordcount;
import backtype.storm.spout.SpoutOutputCollector;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.topology.base.BaseRichSpout;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Values;
import backtype.storm.utils.Utils;
import java.util.Map;
import java.util.Random;
//模拟数据源类
public class RandomSentenceSpout extends BaseRichSpout {
SpoutOutputCollector _collector;
Random _rand;
public void open(Map conf, TopologyContext context, SpoutOutputCollector collector) {
_collector = collector;
_rand = new Random();
}
public void nextTuple() {
Utils.sleep(100);
String[] sentences = new String[]{ "the cow jumped over the moon", "an apple a day keeps the doctor away",
"four score and seven years ago", "snow white and the seven dwarfs", "i am at two with nature" };
String sentence = sentences[_rand.nextInt(sentences.length)];
// System.out.println(sentence+"========");
_collector.emit(new Values(sentence));
}
public void ack(Object id) {
}
public void fail(Object id) {
}
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word"));
}
}
6. Storm的分组机制(stream grouping)
分组是为了让程序并行执行,一个Bolt可以设置为多个Task并发处理数据,Spout产生数据后,该吧数据发送给哪个具体的Task执行,是由grouping决定的。
常见的分组方式:
(1) 随机分组(shuffle grouping):随机分发Tuple到各个Bolt,保证每个任务获得相同数量的Tuple。
(2) 字段分组(Fields grouping):根据指定字段分割数据流,并分组。例如,根据“user-id”字段,相同“user-id”的元组总是分发到同一个任务,不同“user-id”的元组可能分发到不同的任务。
(3) 全部分组(All grouping): tuple被复制到bolt的所有任务。这种类型需要谨慎使用。
(4) 全局分组(Global grouping):全部流都分配到bolt的同一个任务。明确地说,是分配给ID最小的那个task。
(5) 无分组(None grouping):你不需要关心流是如何分组。目前,无分组等效于随机分组。但最终,Storm将把无分组的Bolts放到Bolts或Spouts订阅它们的同一线程去执行(如果可能)。
(6) 直接分组(Direct grouping):这是一个特别的分组类型。元组生产者决定tuple由哪个元组处理者任务接收。
PS: 当然还可以实现CustomStreamGroupimg接口来定制自己需要的分组。
7. Spout的数据来源
Strom本身不具备存储数据的功能,它计算的数据是以Spout为入口从其它地方读进来的。Spout可以从各种数据仓库中读取数据,比如Oracle、Kafka、HDFS、HBase中,最方便的可能是从Kafka中读取,Storm源码中已有Strom和Kafka结合的类SuportConfig,只要配置一下即可实现从kafka中读取数据。
8. 实时计算业务场景举例
(1) 实时统计
这个很好理解,之前做的都是基于MapReduce的离线计算,利用Strom的特性可以对于某些时效性很强的业务提供强有力的数据支撑,比如秒杀活动、5分钟内的视频点击量、股票走势分析等等。
(2) 日志分析
有些日志可能需要经过处理才入库,为了减少数据落地的弊端,可以先利用strom进行处理再入库。
(3) 车辆超速预警系统
实时分析过往车辆的数据,一旦车辆数据超过预设的临界值 —— 便触发一个trigger并把相关的数据存入数据库。